To optimize mappings that read from a partitioned Hive source, you typically add filter conditions on a relational data object to remove rows at the source. The filter limits the data that flows through the mapping pipeline which gives a performance benefit. However, when the Blaze engine reads from a Hive source with a filter condition, the engine interprets the filters as SQL overrides, translates into multiple grid tasks, and adds a performance overhead.
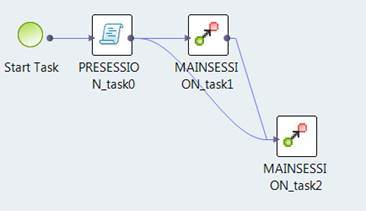
The Blaze engine translates the filters into the following grid tasks:
A grid task to create a HiveServer2 job for the filter override to stage the intermediate data.
A grid task to operate against the staged data and to apply the downstream mapping logic.
For example, the following image shows the Blaze engine execution plan with two grid tasks for a passthrough mapping with a filter:
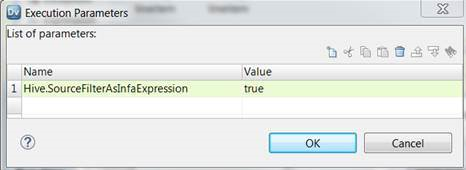
To avoid the performance overhead, set the following custom flag as an advanced property of the mapping:
Hive.SourceFilterAsInfaExpression = true
If multiple mappings require the flag, add the custom flag at the Data Integration Service level.
The following image shows the custom flag that you added as an execution parameter for the mapping:
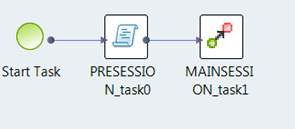
The following image shows the Blaze engine execution plan with a single grid task after you set the custom flag:
Use a valid Informatica expression as a filter condition. The filter condition must not refer to the table name. For example, instead of
LineItem.l_tax > $dataasofdate
, use
l_tax > $dataasofdate
.
The following image shows the
Query
view of the relational data object where you define the filter condition: