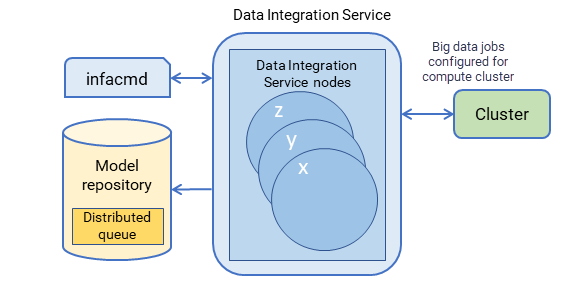
The Data Integration Service uses a distributed queue to store job information until resources are available to run the job. The distributed queue is stored in the Model repository and is shared by the backup node, if one exists, or by all nodes in the grid.
When you run a mapping job or workflow mapping task, the Data Integration Service adds the job to the queue. The job state appears as "Queued" in the Administrator tool contents panel. When resources are available, the Data Integration Service takes a job from the queue and runs it.
The following image shows the location of the distributed queue:
Consider the following queueing process:
A client submits a job request to the Data Integration Service, which stores job metadata in the distributed queue.
When the Data Integration Service node has available resources, the Data Integration Service retrieves the job from the queue and sends it to the available node for processing.
If a node fails while running a job, the job can fail over to another node. Any back-up node or node in the grid can take jobs from the queue.
The interrupted job runs on the new node.
When you run a job that cannot be queued, the Data Integration Service immediately starts running the job. If there are not enough resources available, the job fails, and you must run the job again when resources are available.
The following jobs cannot be queued:
Jobs that cannot be deployed, such as previews and profiles