The Data Integration Service runs mappings, workflows, and other jobs that a developer deploys from clients. The Data Integration Service uses an internal process to assess the job, create an execution plan, and process the job as a series of tasks. Depending on how you configure the Data Integration Service, the process runs the tasks on the Data Integration Service or sends the job for processing to a compute cluster.
When you run a mapping or other job on the Data Integration Service, the Data Integration Service saves the mapping request in a queue. The Data Integration Service mapping service takes the job from the queue when nodes are available to run the job, and creates an execution workflow. The Data Integration Service then processes the execution workflow natively or sends workflow tasks to the cluster for processing.
When a compute cluster receives a job from the Data Integration Service, it assigns each job and each child task a YARN ID. The Data Integration Service stores the YARN ID in the Model repository database to aid in tracking jobs.
The job is complete when the client receives the Complete status from the Data Integration Service.
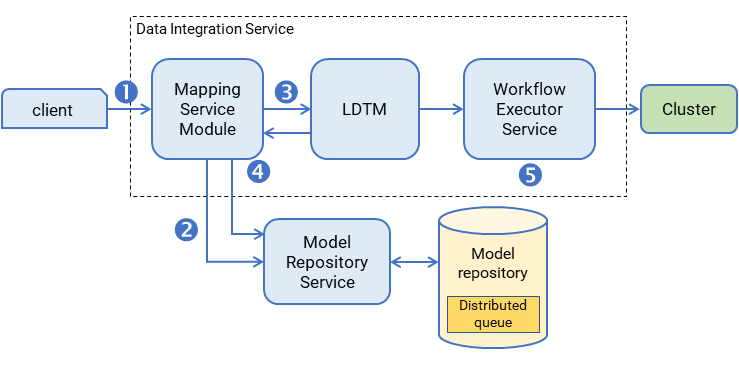
The following image shows an overview of Data Integration Service processing:
A client submits a mapping execution request to the Data Integration Service. The Mapping Service Module receives the request and stores the job in the queue.
The Mapping Service Module connects to the Model Repository Service to fetch mapping metadata from the Model repository.
The Mapping Service Module passes the mapping to the Logical Data Transformation Manager (LDTM).
The LDTM compiles the mapping and generates the Spark execution workflow. It stores the execution workflow in the Model repository.
The LTDM pushes the execution workflow through the Workflow Executor Service to the cluster for processing.
You can tune the Data Integration Service and run-time engines for large dataset processing to ensure that sufficient resources are available to perform jobs.