You can leverage the cloud deployment of Big Data Management on Amazon EMR to implement a data lake solution.
When you have data in different repositories owned by a wide spectrum of stakeholders, you can import the data from disparate sources to a data lake to enable access to all the users in your organization.
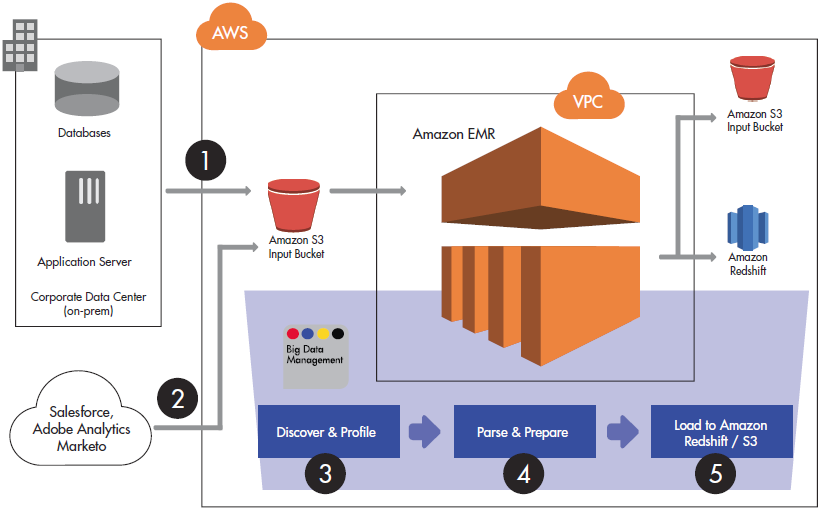
The following image shows how you can implement a data lake solution using Big Data Management and Amazon EMR, Amazon S3, and Amazon Redshift.
Offload infrequently used data and batch load raw data to a defined landing zone in an Amazon S3 bucket. For a data lake, you load raw transactional and multi-structured data directly to Amazon S3, freeing up space in the current Enterprise Data Warehouse..
Collect and stream data generated by machines and sensors, including application and weblog files, directly to Amazon S3 instead of staging it in a temporary file system or the data warehouse.
Discover and profile data stored on Amazon S3. Profile data to better understand its structure and context. Adding requirements for enterprise accountability, control, and governance for compliance with corporate and governmental regulations and business service level agreements.
Parse and prepare data from weblogs, application server logs or sensor data. Typically, these data types are either in multi-structured or unstructured formats which can be parsed to extract features and entities, and data quality techniques can be applied. You can execute pre-built transformations and data quality and matching rules natively in Amazon EMR to prepare data for analysis.
After you cleanse and transform data on Amazon EMR, move high-value curated data from EMR to an Amazon S3 output bucket or to Amazon Redshift. From there, users can directly access data with BI reports and applications.
In this process, Amazon EMR does not copy the data to local disk or HDFS. Instead, mappings open multithreaded HTTP connections to Amazon S3, pull data to the Amazon EMR cluster, and process data in streams.