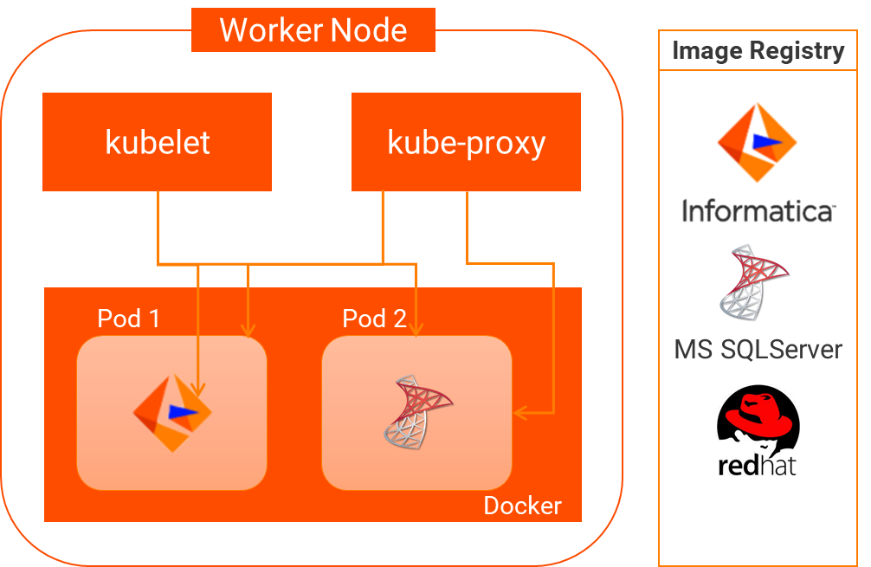
The worker node contains kubelet and kube-proxy that both connects to the pods within the docker. Informatica processes along with different OS images that runs on the worker node.
The following node components are needed on a Kubernetes cluster and can also run on master node:
kubelet
A kubelet takes information from the master node and ensures that any pods assigned to it are running and configured in the desired state. All Kubernetes nodes must have a kubelet. The kubelet creates a pod, makes it container ready, and performs a readiness check.
kube-proxy
Watches on all services and maintains the network configuration across all elements of the cluster.
Container runtime
Engine that runs the containers. Containers at runtime such as Docker or RKT are based on the setup configured.
The following image shows the Kubernetes worker node components:
The image shows how the worker node contains the Kubelet and the kube-proxy that is connected to the pods. The kubelet helps to control the state of the files. The docker image registry stores the images of the Informatica binaries, Redhat operating system, and Microsoft SQL Server database. There are two pods that contain different images. Pod 1 contains Informatica domain and services with Red Hat operating system and Pod 2 contains the Microsoft SQL server database. Both the pods resides in a Docker container runtime that you can run as a docker image or a service regular on a system.