The Write_GoodMatches_Customer target table receive rows from the Standard Output group. The table receives unique records and it receives records that are duplicates. These records do not require manual review.
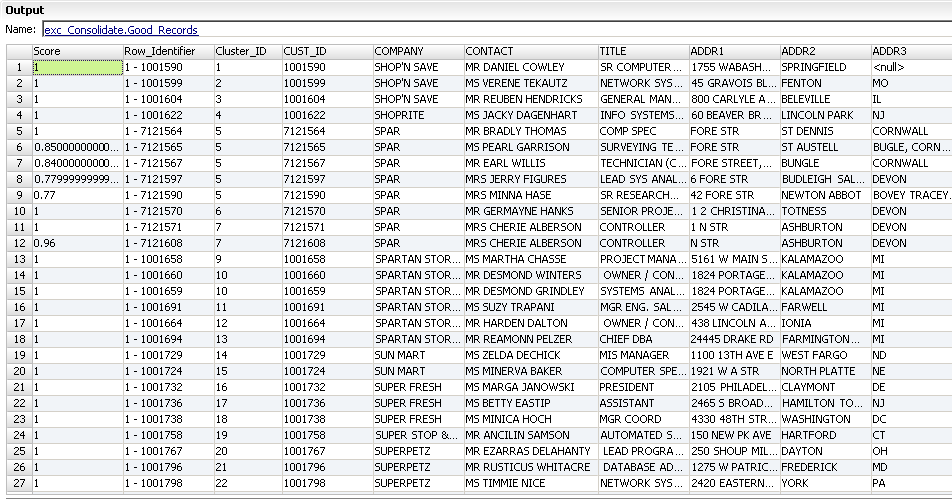
The following figure shows the Standard Output records that the Exception transformation returns:
The record contains the following fields:
Score
Match score that indicates the degree of similarity between a record and another record in the cluster. Records with a match score of one are duplicate records that do not need review. A cluster in which any record has a match score below the lower threshold is not a duplicate cluster.
Row_Identifier
A row number that uniquely identifies each row in the table. For this example, the row identifier contains the customer ID.
Cluster ID
A unique identifier for a cluster. Each record in a cluster receives the same cluster ID. The first four records in the sample output data are unique. Each record has a unique cluster ID. Rows five to nine belong to cluster five. Each record in this cluster is a duplicate record because of similarities in the address fields.
Source Data Fields
The Standard Output table group also receives all the source data fields.