Data Ingestion and Replication
- Data Ingestion and Replication
- All Products
 ASK INFAPreview
ASK INFAPreview

Path Type | Value |
|---|---|
Folder Path | Enter a folder name or use variables to create a folder name.
For example, to organize your data by date, schema, table, and
load time, enter
{yyyy}/{mm}/{dd}/{SchemaName}/{TableName}/{Timestamp} |
Timestamp | You can select from the following values:
|
Schema Name | You can select from the following values:
|
Table Name | You can select from the following values :
|

Field
| Description
| Default
|
|---|---|---|
Task Target Directory
| Name of a root directory to use for storing output files for an incremental load task.
If you select the
Connection Directory as Parent option, you can still optionally specify a task target directory. It will be appended to the parent directory to form the root for the data, schema, cycle completion, and cycle contents directories.
This field is required if the {TaskTargetDirectory} placeholder is specified in patterns
for any of the following directory fields. | None
|
Connection Directory as Parent
| Select this check box to use the parent directory specified in the connection properties.
This field is not available for the Microsoft Fabric OneLake target.
| Selected
|
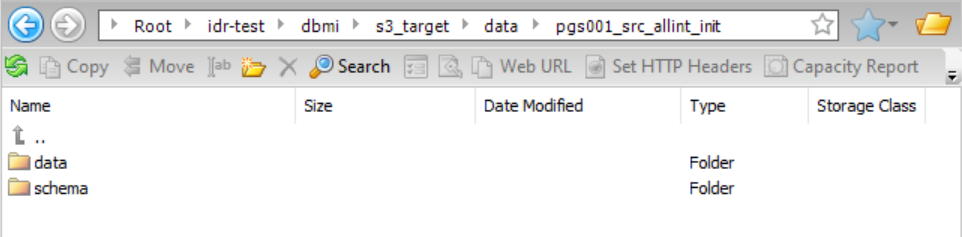
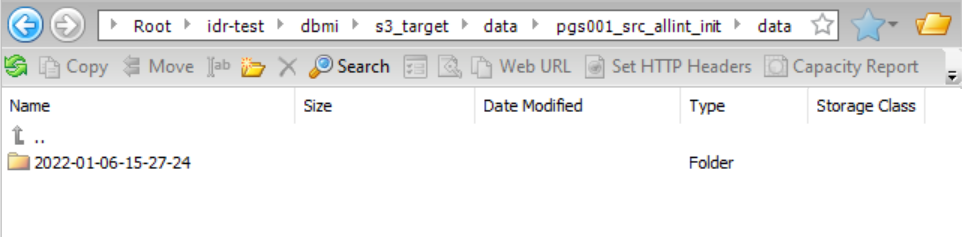
Data Directory
| Path to the subdirectory that contains the data files.
In the directory path, the {TableName} placeholder is required if data and schema files are
not partitioned by CDC cycle.
| {TaskTargetDirectory}/data/{TableName}/data
|
Schema Directory
| Path to the subdirectory in which to store the schema file if you do not want to store it in the data directory.
In the directory path, the {TableName} placeholder is required if data and schema files are not partitioned by CDC cycle.
| {TaskTargetDirectory}/data/{TableName}/schema
|
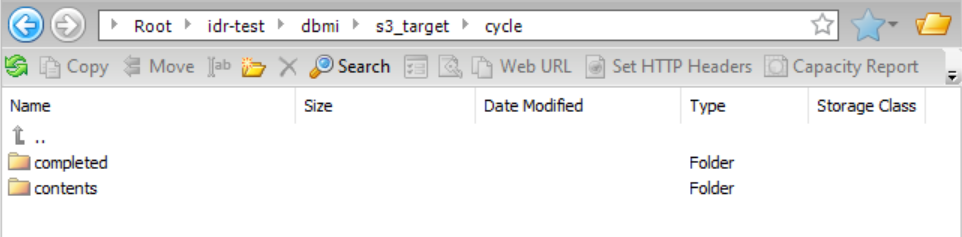
Cycle Completion Directory
| Path to the directory that contains the cycle completed file.
| {TaskTargetDirectory}/cycle/completed
|
Cycle Contents Directory
| Path to the directory that contains the cycle contents files.
| {TaskTargetDirectory}/cycle/contents
|
Use Cycle Partitioning for Data Directory
| Causes a timestamp subdirectory to be created for each CDC cycle, under each data directory.
If this option is not selected, individual data files are written to the same directory without a timestamp, unless you define an alternative directory structure.
| Selected
|
Use Cycle Partitioning for Summary Directories
| Causes a timestamp subdirectory to be created for each CDC cycle, under the summary contents and completed subdirectories.
| Selected
|
List Individual Files in Contents
| Lists individual data files under the contents subdirectory.
If
Use Cycle Partitioning for Summary Directories is cleared, this option is selected by default. All of the individual files are listed in the contents subdirectory unless you can configure custom subdirectories by using the placeholders, such as for timestamp or date.
If
Use Cycle Partitioning for Data Directory is selected, you can still optionally select this check box to list individual files and group them by CDC cycle.
| Not selected if
Use Cycle Partitioning for Summary Directories is selected.
Selected if you cleared
Use Cycle Partitioning for Summary Directories .
|
Path Type | Value |
|---|---|
Folder Path | Enter {TaskTargetDirectory} for a task-specific base
directory on the target to use instead of the S3 folder path
specified in the connection properties. |
Timestamp | You can select from the following values:
Use {Timestamp}, {yy}, {yyyy}, {mm}, and {dd} in
directory patterns to insert specific date and time
information into directory names for organizing data. When
you specify these placeholders in directory patterns for
data, contents, and completed directories, these
placeholders represent the time when the CDC cycle began.
For the schema directory, these placeholders represent the
time when the entire CDC job started, not just the
cycle. |
Schema Name | You can select from the following values:
|
Table Name | You can select from the following values:
|