Data Ingestion and Replication
- Data Ingestion and Replication H2L
- All Products
 ASK INFAPreview
ASK INFAPreview

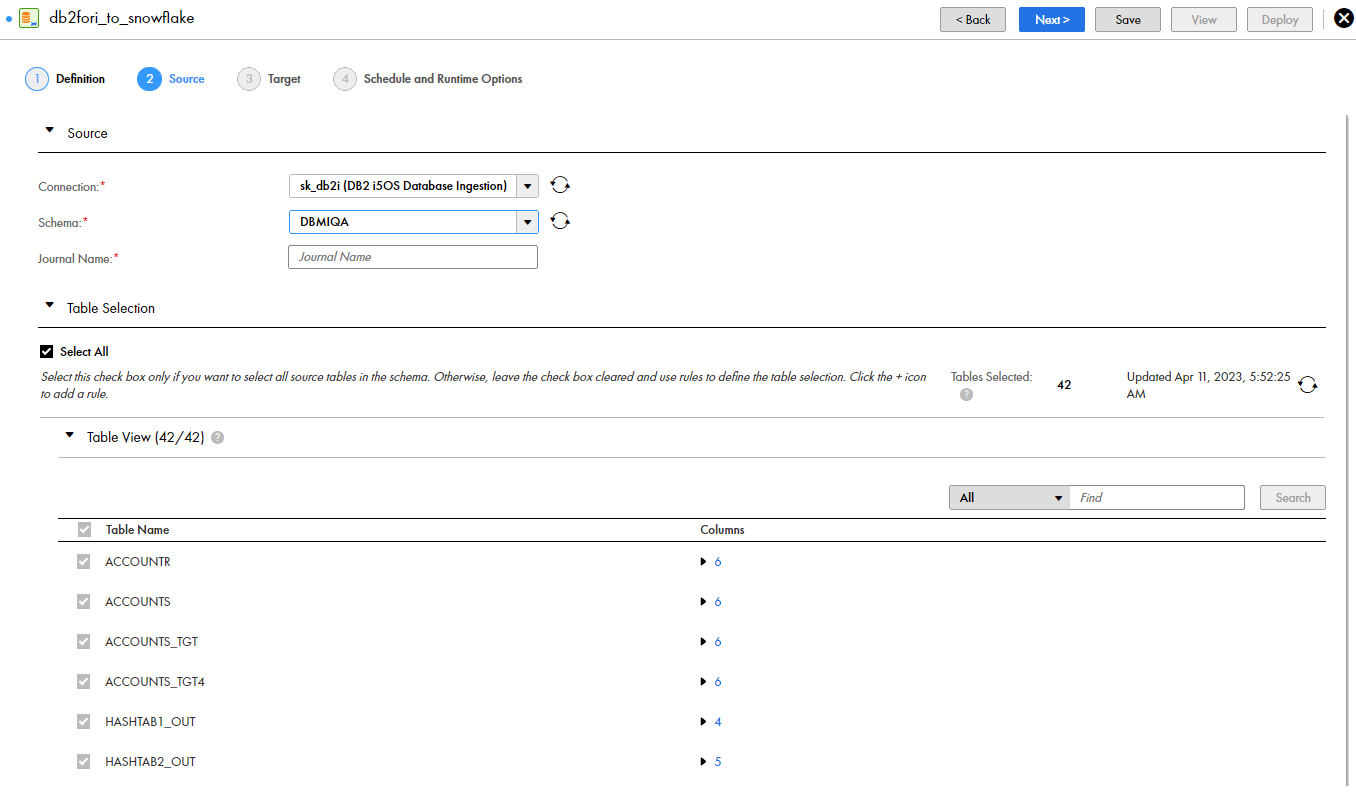
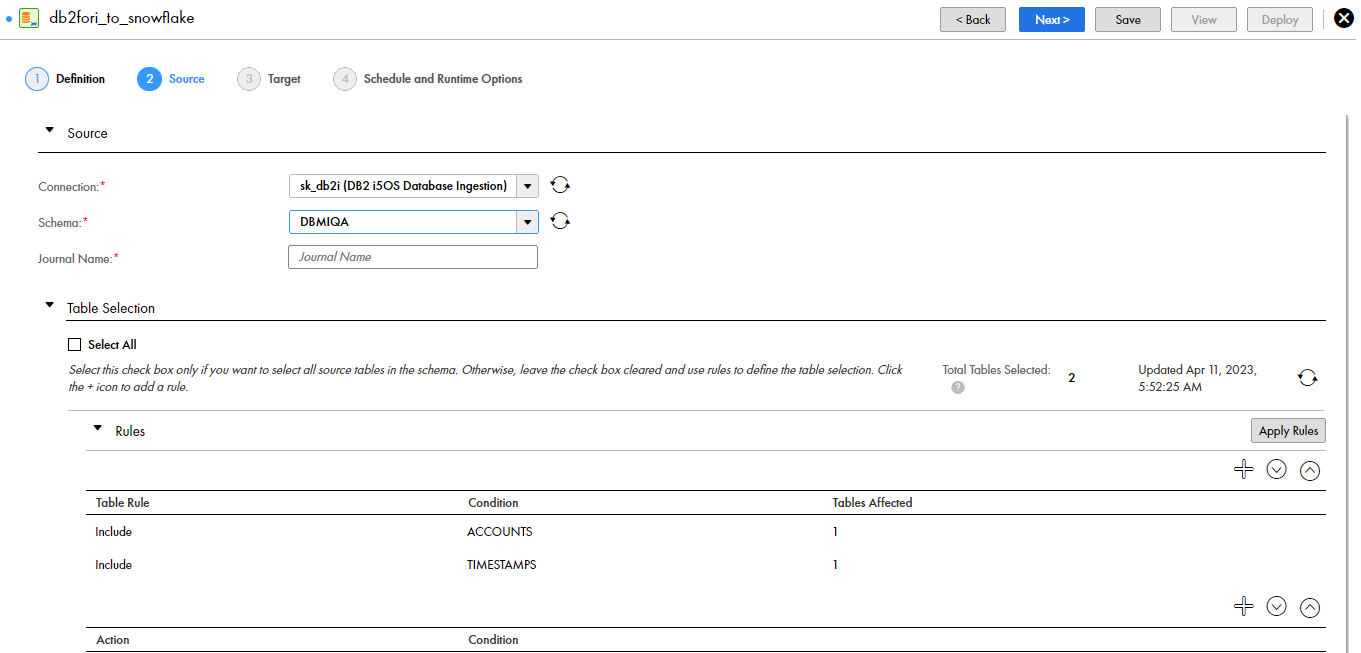
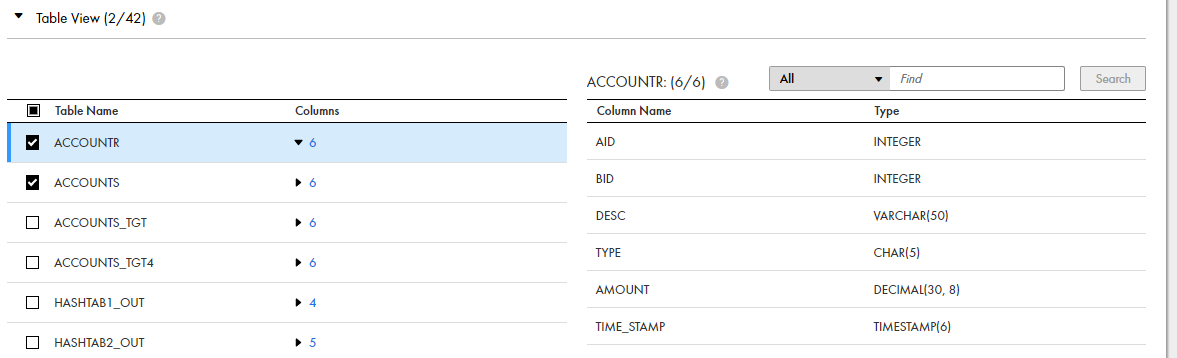
status,schema_name,table_name,object_type,column_name,comment
Field
| Description
|
|---|---|
status
| Indicates whether Mass Ingestion Databases excludes the source table or column from processing because it has an unsupported type. Valid values are:
|
schema_name
| Specifies the name of the source schema.
|
table_name
| Specifies the name of the source table.
|
object_type
| Specifies the type of the source object. Valid values are:
|
column_name
| Specifies the name of the source column. This information appears only if you selected the
Columns check box.
|
comment
| Specifies the reason why a source object of an unsupported type is excluded from processing even though it matches the selection rules.
|
Property
| Description
|
|---|---|
Enable Persistent Storage
| Select this check box to enable persistent storage of transaction data in a disk buffer so that the data can be consumed continually, even when the writing of data to the target is slow or delayed.
Benefits of using persistent storage are faster consumption of the source transaction logs, less reliance on log archives or backups, and the ability to still access the data persisted in disk storage after restarting a database ingestion job.
|
Initial Start Point for Incremental Load
| Set this field if you want to customize the position in the source logs from which the
database ingestion job starts reading change records the first time it runs.
Options are:
The default is
Latest Available .
The
Initial Start Point for Incremental Load option pertains only to the initial run of a job. Thereafter, if you resume a stopped or aborted job, the job begins propagating source data from where it last left off.
|
