Data Integration Connectors
- Data Integration Connectors H2L
- All Products

import java.nio.charset.StandardCharsets;
<variable_name>= new String(data, StandardCharsets.UTF_8); generateRow();
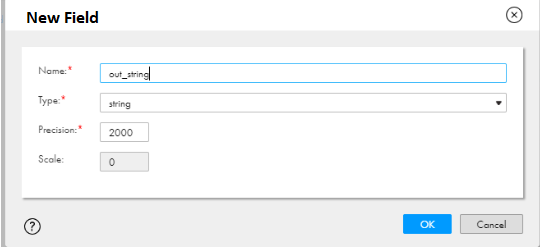
out_string= new String(data, StandardCharsets.UTF_8); generateRow();