Unicode provides a technically more competent way of implementing international systems, and simplifies the storage, transfer and display of multi-lingual data. However, Unicode in itself does little to address the problems of searching and matching identity data.
Unicode does not know
that BILL is a form of WILLIAM
that
is a form of ALEKSEI
that
is the Arabic form of MOHAMMED
that
is essentially just "noise" in a Chinese company name
that Ann Jakson could be a form of Anne Jackson-Brown
While it may be natural to think that Unicode can help unify data across countries and languages, Unicode does not help find and match identity data even within one language, let alone between languages. Unicode can actually lead to an increase in variation of the identity data stored in a database if the data is allowed to be captured and stored in a variety of character sets.
Thus, the bilingual Greek/English data entry operator in England opening an account for a Greekborn British national (who has provided their Greek name on the application form), enters it in Greek because the system allows it. Worse, part or all of the name may even look like English (e.g. the name POZANA) and be stored as though it were an English name.
In the majority of systems, data entry should be restricted to the character set of the primary locale and converted to Unicode by the system. And it is essential that this locale information be kept and stored so that it is available for use by localized data matching algorithms. Conversion to and from Unicode will require that it be done consistently. Conversion of old data to Unicode will still inherit all the error and variation in the old character forms. Users will still enter new data with the old character conventions, and of course continue to make mistakes.

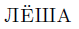 is a form of ALEKSEI
is a form of ALEKSEI 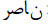 is the Arabic form of MOHAMMED
is the Arabic form of MOHAMMED  is essentially just "noise" in a Chinese company name
is essentially just "noise" in a Chinese company name 