Identity Resolution
- Identity Resolution 10.0
- All Products

Partitions
| Fuzzy SSA-NAME3 Key
| Compressed Identity Data
|

Value
| Description
|
|---|---|
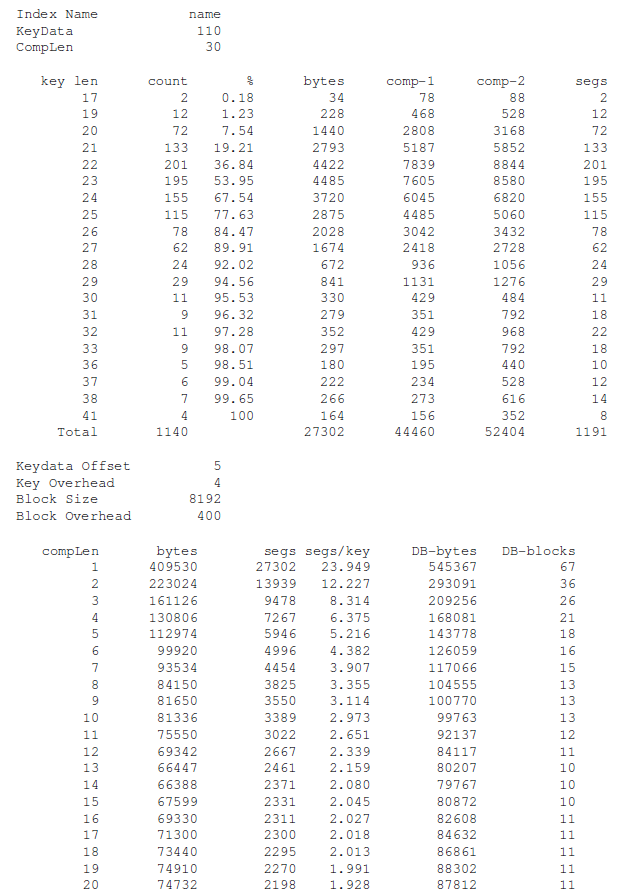
IndexName
| the name of the IDX
|
KeyData
| the sum of the length of the IDT columns (the Identity Data, uncompressed)
|
CompLen
| Compress-Key-Data(n) value
|
Key Len
| the length of the Identity Data after compression
|
Count
| the number of records with this
KeyLen |
Bytes
| KeyLen * Count |
Comp-1
| total bytes to store
Count records with
KeyLen using Method 1 (1 segment only)
|
Comp-2
| total bytes to store
Count records with
KeyLen using Method 0 (multiple segments)
|
Segs
| the number of segments required to store
Count records of
KeyLen |
Value
| Description
|
|---|---|
KeyDataOffset
| length of the Fuzzy Key including any partition
|
KeyOverhead
| the overhead associated with storing the segment on the host DBMS (assumed)
|
Blocksize
| DBMS block size (assumed)
|
BlockOverhead
| DBMS overhead when storing records within a block including control structures and padding (assumed)
|
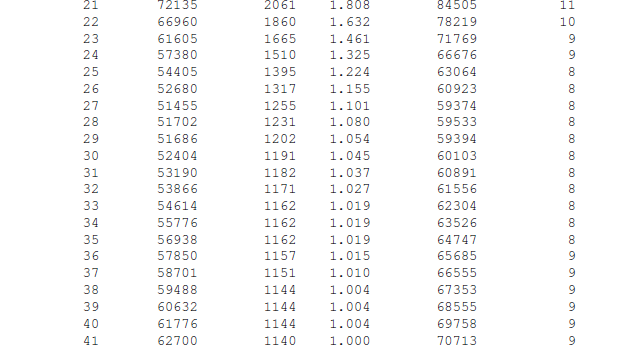
compLen
| n from
Compress-Key-Data(n) |
Bytes
| the number of bytes required to store segments of this size
|
Segs
| the number of segments used
|
Segs/Key
| the average number of segments per IDX record.
|
DB-Bytes
| the number of bytes for segment of this size (scaled up by
KeyOverhead )
|
DB-Blocks
| the number of blocks for segments of this size (based on the
Blocksize and
BlockOverhead )
|
