Identity Resolution
- Identity Resolution 10.0
- All Products

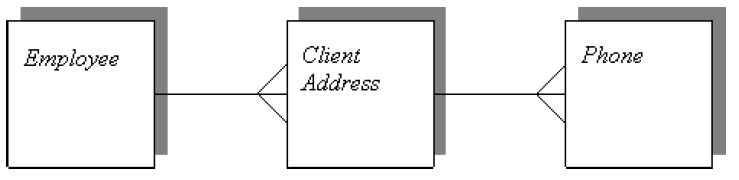
Emp_Id | Name |
|---|---|
E001 | Joe Programmer |
Company_Id | Address | FK_Emp_Id |
|---|---|---|
C001 | 3 Lonsdale | St E001 |
C002 | 19 Torrens | St E001 |
C003 | 4 Rudd | St E001 |
Company_Id | Phone |
|---|---|
C001 | 62575400 |
C001 | 62575401 |
C002 | 98940000 |
C003 | 52985500 |
C003 | 52985501 |
C003 | 52985502 |
Emp_Id | Name | Company_Id | Address | Phone |
|---|---|---|---|---|
E001 | Joe Programmer | C001 | 3 Lonsdale St | 62575400 |
E001 | Joe Programmer | C001 | 3 Lonsdale St | 62575401 |
E001 | Joe Programmer | C002 | 19 Torrens St | 98940000 |
E001 | Joe Programmer | C003 | 4 Rudd St | 52985500 |
E001 | Joe Programmer | C003 | 4 Rudd St | 52985501 |
E001 | Joe Programmer | C003 | 4 Rudd St | 52985502 |
Column | Value |
|---|---|
Emp_Id | E001 |
Name | Joe Programmer |
Company_Id [1] | C001 |
Company_Id [2] | C002 |
Company_Id [3] | C003 |
Address [1] | 3 Lonsdale St |
Address [2] | 3 Lonsdale St |
Address [3] | 19 Torrens St |
Address [4] | 4 Rudd St |
Address [5] | 4 Rudd St |
Address [6] | 4 Rudd St |
Phone [1] | 62575400 |
Phone [2] | 62575401 |
Phone [3] | 98940000 |
Phone [4] | 52985500 |
Phone [5] | 52985501 |
Phone [6] | 52985502 |
