Identity Resolution
- Identity Resolution 10.1
- All Products

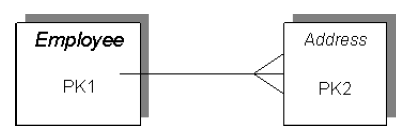
I1 N1 A1 I1 N1 A2 I1 N1 A3 I1 N2 A1 I1 N2 A2 I1 N2 A3 I1 N3 A1 I1 N3 A2 I1 N3 A3
I1 N1 N2 A1 A2 I1 N3 A3
I1 N1 A1 A2 A3 I1 N2 A1 A2 A3 I1 N3 A1 A2 A3
I1 N1 A1 A2 I1 N1 A3 I1 N2 A1 A2 I1 N2 A3 I1 N3 A1 A2 I1 N3 A3
