Configuring a Mapping to Run in a Non-native Environment
Configuring a Mapping to Run in a Non-native Environment
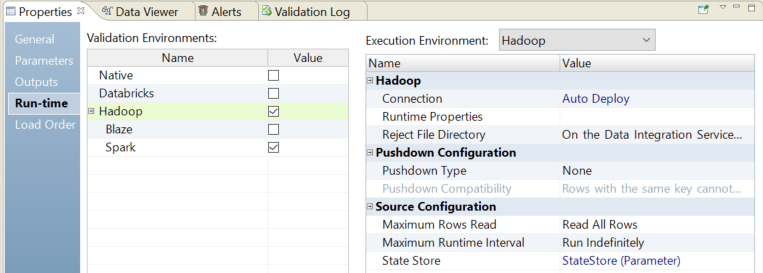
You can configure a mapping to run in a non-native environment. To configure a mapping, you must select a validation environment and an execution environment.
Select a mapping from a project or folder from the
Object Explorer
view to open in the editor.
In the
Properties
view, select the
Run-time
tab.
Select
Hadoop
,
Databricks
, or both as the value for the validation environment.
When you select the Hadoop environment, the Blaze and Spark engines are selected by default. Disable the engines that you do not want to use.
Select
Hadoop
or
Databricks
for the execution environment.
Select
Connection
and use the drop down in the value field to browse for a connection or to create a connection parameter:
To select a connection, click
Browse
and select a connection.
To create a connection parameter, click
Assign Parameter
.
Configure the rest of the properties for the execution environment.