When you run a job on the Databricks Spark engine, the Data Integration Service pushes the processing to the Databricks cluster, and the Databricks Spark engine runs the job.
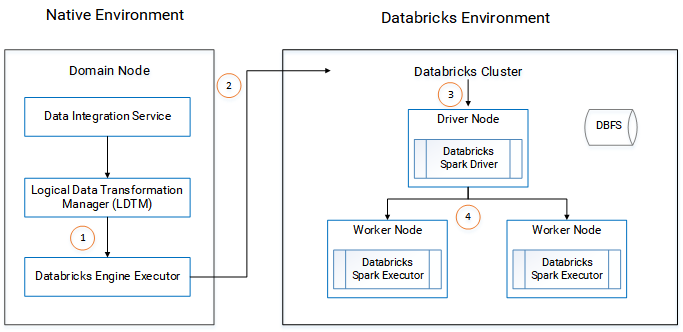
The following image shows the components of the Informatica and the Databricks environments:
The Logical Data Transformation Manager translates the mapping into a Scala program, packages it as an application, and sends it to the Databricks Engine Executor on the Data Integration Service machine.
The Databricks Engine Executor submits the application through REST API to the Databricks cluster, requests to run the application, and stages files for access during run time.
The Databricks cluster passes the request to the Databricks Spark driver on the driver node.
The Databricks Spark driver distributes the job to one or more Databricks Spark executors that reside on worker nodes.
The executors run the job and stage run-time data to the Databricks File System (DBFS) of the workspace.