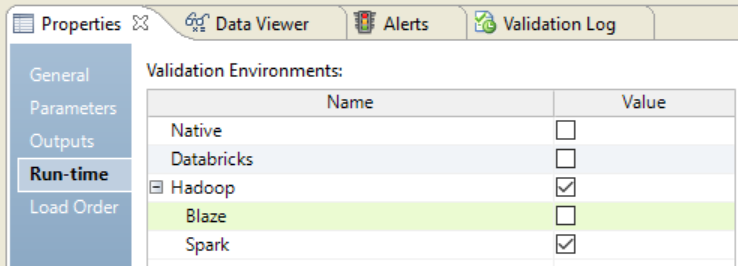
The validation environment indicates whether the Developer tool validates the mapping definition for the native or non-native execution environment. When you run a mapping in the native environment, the Data Integration Service processes the mapping.
Based on your license, you can run a mapping in the non-native environment. When you run a mapping in the non-native environment, the Data Integration Service pushes the mapping execution to the compute cluster through a cluster connection. The compute cluster processes the mapping.
When you choose the Hadoop execution environment, you can select the Blaze or Spark engine to process the mapping.
The following image shows the validation environment:
Choose native, Hadoop, and Databricks environments in the following situations:
You want to test the mapping in the native environment before you run the mapping in a non-native environment.
You want to define the execution environment value in a parameter when you run the mapping.
If you choose all environments, you must choose the execution environment for the mapping in the run-time properties.
If you run the mapping in the Hadoop environment, Informatica recommends choosing the Spark engine for new mapping development.