Data Archive uses the Data Vault Service to move data to the Data Vault.
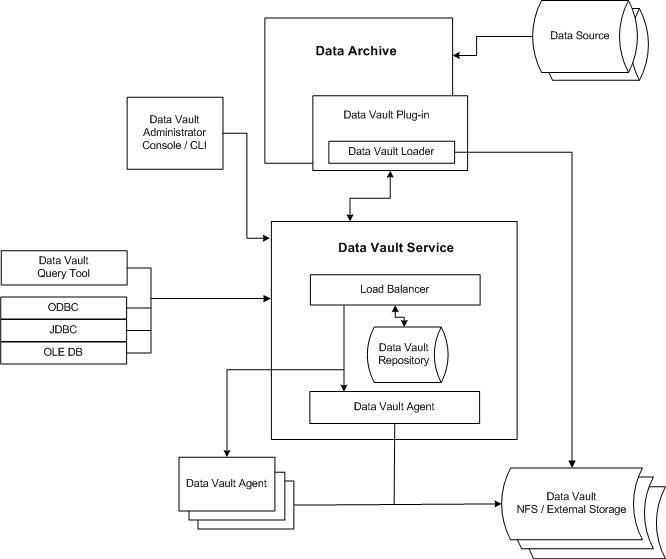
The following diagram illustrates the Data Vault architecture:
Set up a job in Data Archive to archive source data to the Data Vault. When you run the archive job, Data Archive calls the Data Vault Loader to move data to the Data Vault. You can set up the Data Vault to use third-party storage systems such as EMC Centera, Hadoop Distributed File System (HDFS), or Hitachi Content Platform (HCP).
The Data Vault load balancer generates metadata in the Data Vault repository for the archived data. The load balancer calls a Data Vault Agent to access the Data Vault and process client requests.
Use the Data Vault Administration Tool or command line program to monitor and administer the Data Vault components.
You can use ODBC- or JDBC-compliant query or business intelligence tools to access the data in the Data Vault. On Windows, you can also use the Data Vault SQL Tool that ships with the Data Vault to query the data in the Data Vault.
Use the Data Archive options and tools to access the Data Vault. For example, use the Data Validation option to verify that the data moved to the Data Vault is valid. You can also use the Data Discovery portal to search the data in the Data Vault.