The clustering job may be stopped and/or restarted. The clustering process can only be stopped in between the steps or during the CLUSTER phase itself, not during other steps such as loading keys, sorting, etc.
This can be useful in the following circumstances:
While you are running a large clustering and you wish to take periodic backups of the database and index files
You wish to stop the clustering process before it finishes so that you may view the intermediate results and assess its performance
The job can be interrupted manually and placed into a "" by using the relevant features available in the DCE Console window:
Monitor the Clustering Job
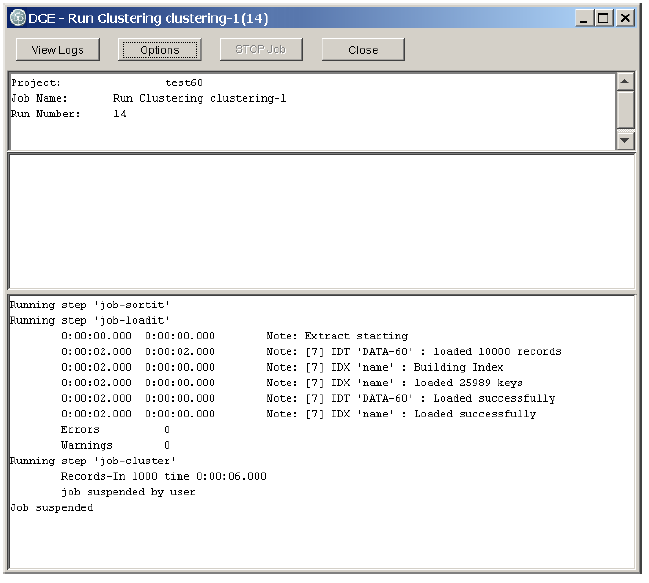
While the clustering process is running, make sure that the Clustering job progress window, such as below, is visible. If it is not visible, double-click the row that contains the details of the Clustering job in the Launched Jobs panel in the main console window.
Clustering Progress Window indicating "running" status
Pause the job
Click the
Options
button, choose
"Place the current step into a wait state"
option and click
OK
.
If the Clustering process is not running when you click the
Options
button, only the option
"Pause the job after completion of the current step is available"
.
Clustering Progress Window
Shortly the Clustering process enters the wait state, which is indicated by the "Job suspended" message in the progress window.
Clustering Progress window indicating "suspended" status
At this point it is safe to close the Console, shutdown the server and perform any maintenance tasks such as a backup. For backing up the Clustering work done so far by the suspended job refer to the Backing Up the Database and Index section.
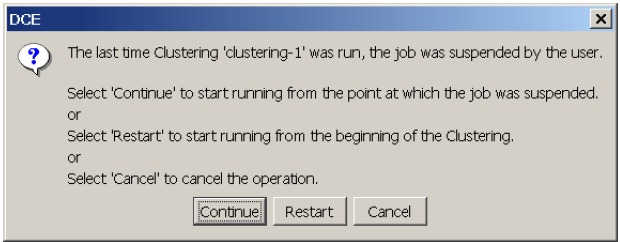
To restart a suspended job
Restart the DCE Server and Console Client and select the
Project
that you were working on. Click the
Run Clustering
button and choose the suspended Clustering name from the list of available Clusterings. You are offered the following options:
Click
Continue
to restart the Clustering from the suspended point.
It is not possible to reliably suspend and restart a Clustering job that reads its input from a changing source, such as a SQL database. If you expect that you need to suspend such a job, then it is recommended that you extract the data temporarily to a sequential file and use this file as the input for the Clustering process.