This example demonstrates the HBase read and write optimization.
HBase Reader Mapping
The mapping reads data from an HBase table and writes the data to an HDFS file that contains approximately 7.5GB of data from 60 million relational records. The HBase table originally had 8 regions. When the table is split into 54 regions, the performance improves by 62%.
The following image shows the mapping:
Result
HBase Writer Mapping
The mapping reads data from an HDFS File that contains approximately 7.5GB of data from 60 million relational records. The mapping uses an Expression transformation to generate the HBase Rowkey and writes the data to an HBase table.
The following image shows the mapping:
Pre-splitting and Result
The HBase table was not originally split. When the HBase table is pre-split into 54 regions, the performance improves by 60%.
The following image shows the result for a pre-split table:
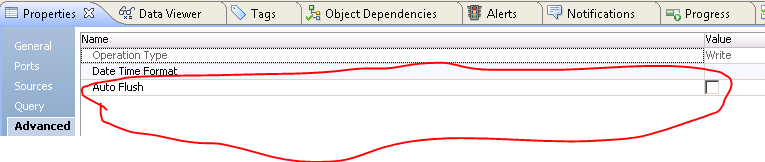
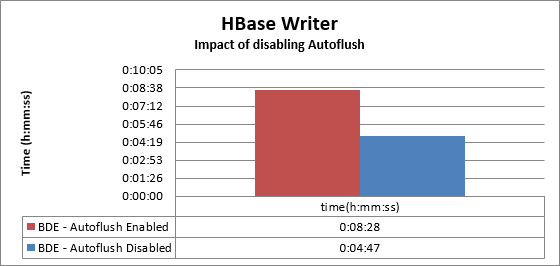
Disabling Auto Flush
When you use PowerExchange for HBase to write data to HBase and disable Auto Flush, performance improves by about 43%.
The following image shows the result after disabling auto flush: