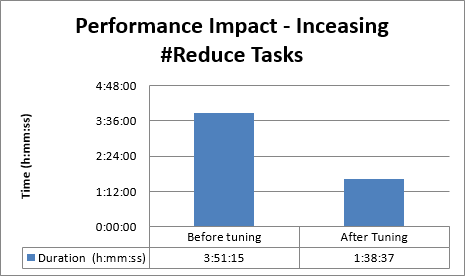
This example demonstrates the benefit of modifying the value of 'mapred.reduce.tasks'.
JSON R2H Mapping
The following image shows the mapping:
The mapping reads two files, Name and Address, that contain normalized data and uses the Data Processor transformation to convert the relational input from the two source files to a JSON denormalized format. It then uses a complex file writer to write the result to an HDFS flat file target.
The Name file is 23 GB and the Address file is 40 GB.
The Data Processor conversion of relational data to a hierarchical JSON object happens during the reduce phase. As the combined input size is about 63 GB, approximately 63 reduce tasks are created with the default value of '-1' for 'mapred.reduce.tasks'.
The Data Processor transformation is CPU intensive. Therefore, increasing the number of reduce tasks can improve performance.
To improve performance, the parameter 'mapred.reduce.task' was modified from '-1' to '210'.
Result
Increasing the number of reduce tasks resulted in a 56% improvement in performance.