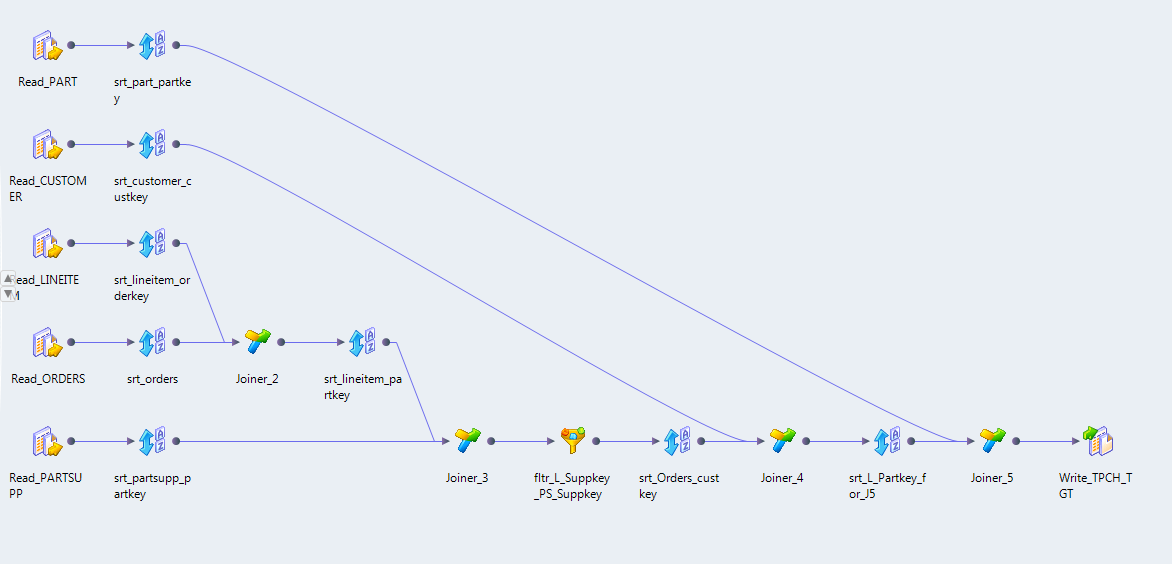
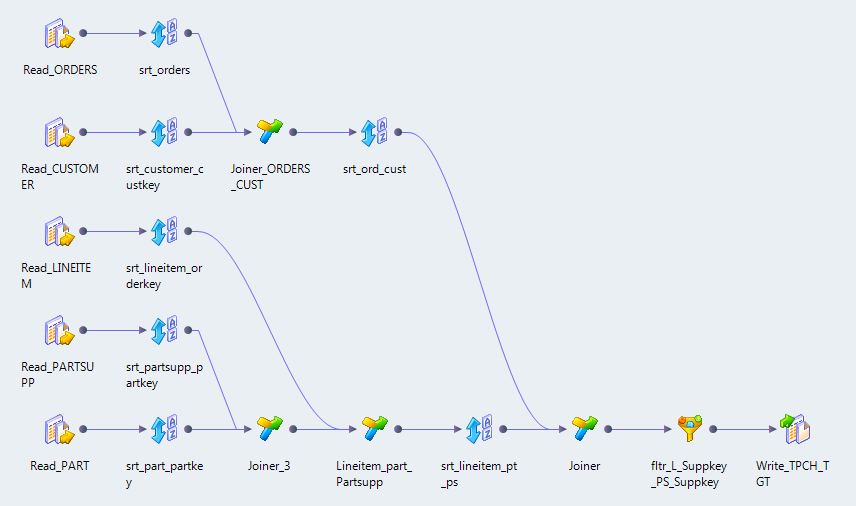
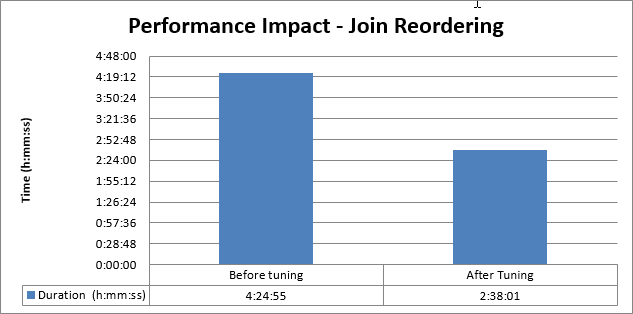
Data Engineering Integration
- Data Engineering Integration H2L
- All Products

Number
| File Name
| Size
|
|---|---|---|
1
| PART
| 23.1 GB
|
2
| CUSTOMER
| 23.08 GB
|
3
| LINEITEM
| 757.86 GB
|
4
| ORDERS
| 168.5 GB
|
5
| PARTSUPP
| 115.2 GB
|