The most effective set up of the partition interim table, therefore, is to use the partitioning key high value to determine if a partition qualifies for processing. The high value for each partition can be stored in the interim table, and then you can build business rules to validate the high value of the partition meets the archive criteria.
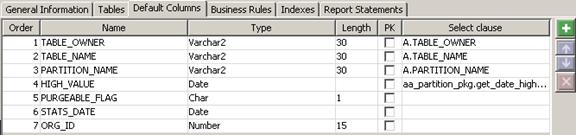
For example, the following figure shows how you can store the high value in the interim table if the partitioning key is a date column:
The following figure shows the select clause:
Note that the high value is populated by using a function, AA_PARTITION_PKG.GET_DATE_HIGH_VALUE. The high_value column in the ALL_TAB_PARTITIONS table is a LONG data type. This limits the ability to query and evaluate the high_value column directly from ALL_TAB_PARTITIONS. The function retrieves the high value and translates the value into a date. The high value of a partition may be:
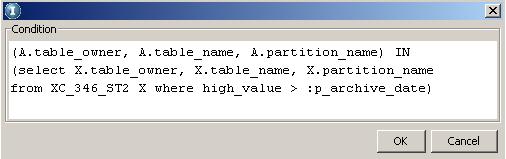
The function translates this value into 01-DEC-2007. The following figure shows how you can then build a business rule to validate that the partition key is less than the archive date:
The following figure shows the condition:
This rule disqualifies any partitions where the high value date is greater than the archive date.
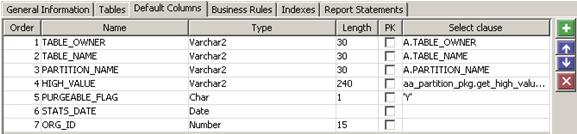
If the partition key is based on a varchar or number column, high value can be retrieved and stored in the interim table using the function, AA_PARTITION_PKG.GET_HIGH_VALUE.
The following figure shows the select clause:
You can now build a business rule to validate the high value that meets the archive or purge criteria. The following syntax illustrates this:
(A.table_owner, A.table_name, A.partition_name) IN (select X.table_owner, X.table_name, X.partition_name from XC_346_ST2 X where high_value < :p_archive_partition_key_value)
Where :p_archive_partition_value is a value determined by the user at run-time.
(A.table_owner, A.table_name, A.partition_name) IN (select X.table_owner, X.table_name, X.partition_name from XC_346_ST2 X where high_value between :p_range_low and :p_range_high )
(A.table_owner, A.table_name, A.partition_name) IN (select X.table_owner, X.table_name, X.partition_name from XC_346_ST2 X where high_value IN (‘AR’,’AP’,’GL’)