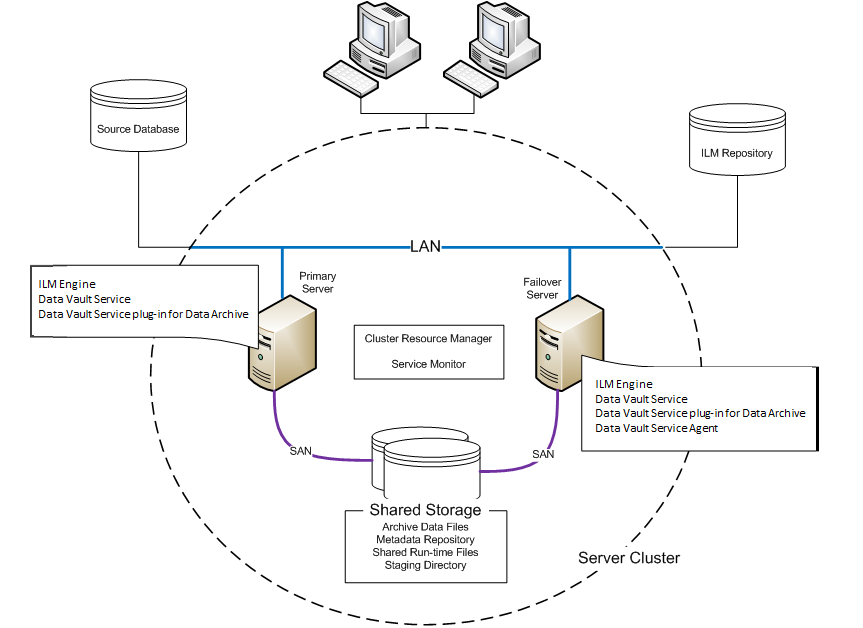
A cluster resource manager (CRM) manages the servers and resources in a server cluster. A service monitoring software detects a node failure and reroutes the workload to another node.
The following diagram shows the configuration of a highly available Data Archive and Data Vault environment:
The server cluster includes the following components:
Cluster resource manager (CRM)
The CRM manages access to the servers and resources in the cluster. It also manages the changeover from one node to another.
Service monitor
The service monitor detects when the primary node is down and triggers the changeover to another node.
Primary server
The primary server is the logical server that performs all archiving processes and requests. It is always in active mode.
The primary server hosts the following Data Archive and Data Vault components:
ILM Engine
Data Vault Service
Data Vault Service plug-in for Data Archive
Failover server
If the primary server fails, the failover server takes over the functions of the primary server and performs all archiving processes and requests. The failover server is in passive mode unless the primary server fails. When it is in passive mode, the failover server can process queries to the Data Vault.
The failover server hosts the following Data Archive and Data Vault components:
ILM Engine
Data Vault Service
Data Vault Service plug-in for Data Archive
Data Vault Service agent
The failover server hosts the same components as the primary server. It hosts an additional Data Vault Service agent to process queries.
The failover server must have the same directory structure as the primary server. For example, if the ILM Engine is installed in the
c:/ILM
directory in the primary server, then the ILM Engine must also be installed in the
c:/ILM
directory in the failover server.
Shared storage
The primary and failover servers connect to the same Data Vault directories. If the server cluster includes multiple storage devices, the primary server and the failover server must have access to a shared drive.
Create the following Data Archive and Data Vault directories:
Directory for the Data Vault repository. For example:
<SANRootDirectory>/Meta/
Directory for the shared run-time files. For example: