Data Engineering Integration
- Data Engineering Integration 10.5.2
- All Products


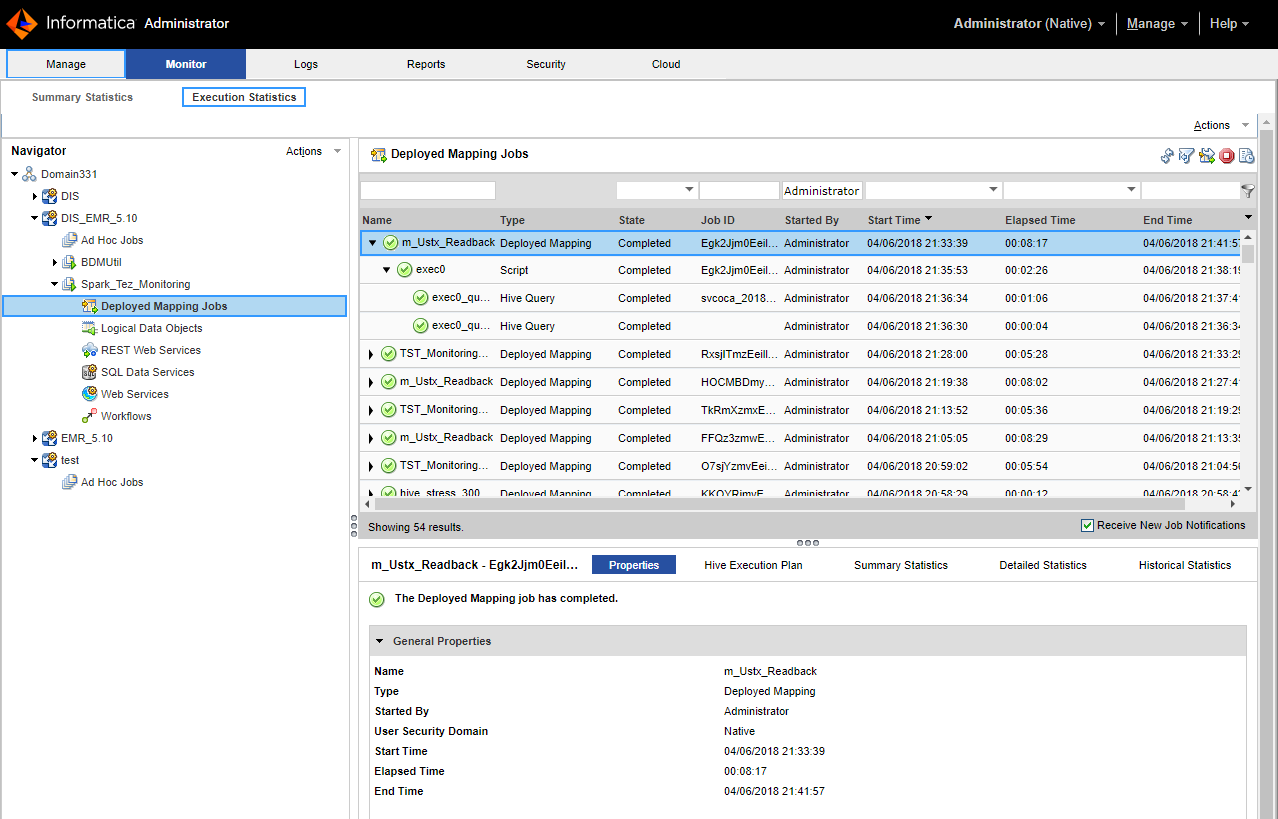

Job Status
| Rules and Guidelines
|
|---|---|
Queued
| The job is in the queue.
|
Running
| The Data Integration Service is running the job.
|
Completed
| The job ran successfully.
|
Aborted
| The job was flushed from the queue at restart or the node shut down unexpectedly while the job was running.
|
Failed
| The job failed while running or the queue is full.
|
Canceled
| The job was deleted from the queue or cancelled while running.
|
Unknown
| The job status is unknown.
|
