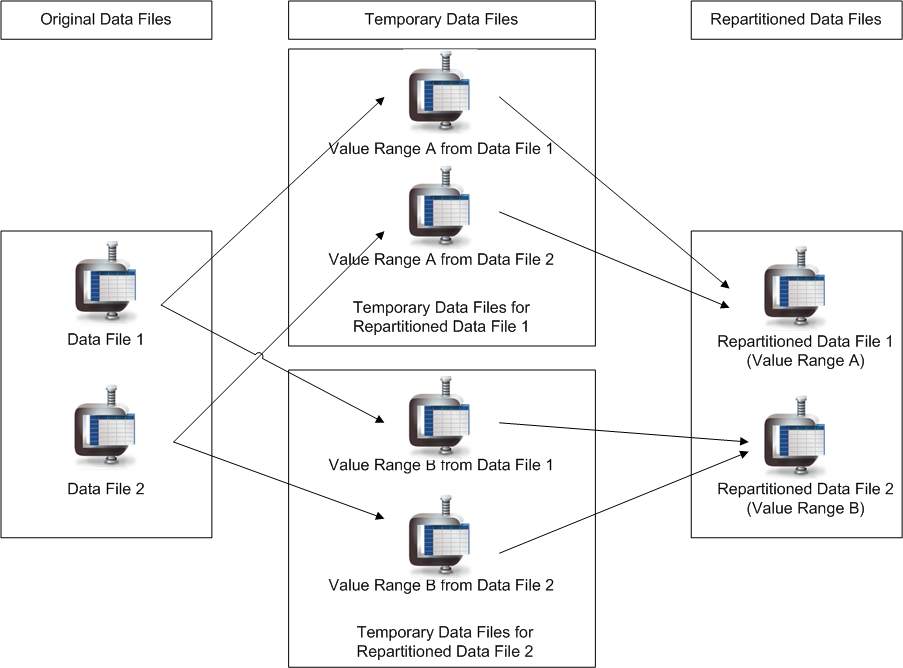
You want to repartition a table that includes two data files. You configure the same row count as the original data files. The final number of repartitioned data files for the table is two.
The following image shows a simplified example of how the Data Vault creates repartitioned data files when the row counts are the same:
To repartition the data, the Data Vault completes the following high-level steps:
The Data Vault calculates the minimum and maximum value range for each repartitioned data file.
Repartitioned data file 1 includes value range A. Repartitioned data file 2 includes value range B.
The Data Vault creates four temporary files to split data from the original data files into the value range of the repartitioned files.
The first temporary file stores data from data file 1 that falls within value range A for repartitioned data file 1. The second temporary file stores data from data file 2 that falls within value range A for repartitioned data file 1. The third temporary file stores data from data file 1 that falls within the value range B for repartitioned data file 2. The fourth temporary file stores data from data file 2 that falls within the value range B for repartitioned data file 2.
The Data Vault merges the two temporary files that contain data in value range A to create repartition data file 1. The Data Vault merges the other two temporary files that contain data in value range B to create repartition data file 2.