When you use Amazon Redshift Connector, PowerExchange for Amazon Redshift, and PowerExchange for Amazon Redshift for PowerCenter to read data from sources, the data are read using multiple partitions that can be configured either using specific values, ranges of values, or partition specific queries. Then, the data are processed in parallel to apply any transformations that you configure.
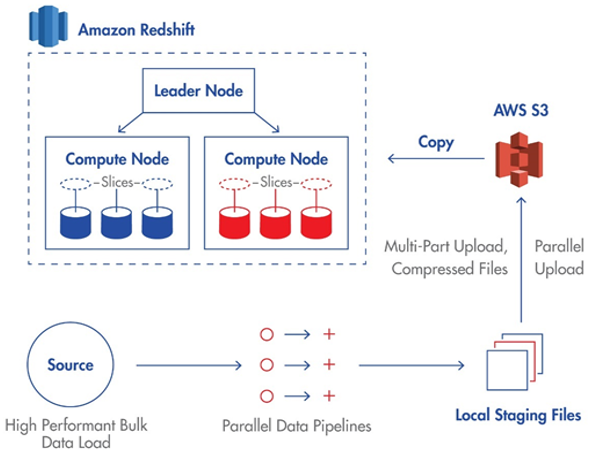
The metadata are fetched from Amazon Redshift based on the number of slices in the compute nodes and splits the data accordingly. The source side partitions can split the data into several stage files that are written in parallel.
The files are loaded into Amazon S3 staging location in parallel with each file uploaded as a single part of multi-part based on the size. Then, loads the data from these files into the Amazon Redshift table by running the COPY command.
The following image shows how data is read from the source, loaded in the Amazon S3 staging file, and written to the Amazon Redshift target: