Amazon Redshift is a cloud-based petabyte-scale distributed data warehouse that the organization uses to analyze and store data.
Amazon Redshift uses columnar data storage, parallel processing, and data compression to store data and to achieve fast query execution. Amazon Redshift distributes data across a cluster of compute nodes and processes the nodes in parallel.
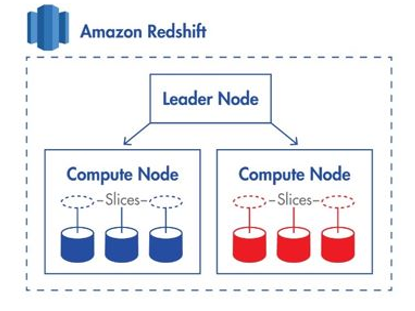
Amazon Redshift uses a cluster-based architecture that consists of a single leader node and compute nodes. The leader node manages the compute nodes and communicates with the external client programs. The leader node interacts with the client applications and communicates with compute nodes. The leader node takes query requests such as JDBC or ODBC interface, performs query planning, and then distributes the SQL query across compute nodes for massive scale and performance.
A compute node stores data and runs queries for the leader node. Any client that uses a PostgreSQL driver can communicate with Amazon Redshift. The ANSI standard SQL interface makes it easy to point Business Intelligence and Analytics Visualization tools at Amazon Redshift for interactive analytic queries.
The following image shows the overview of an Amazon Redshift cluster: