When you read data from an Amazon Redshift source, Informatica recommends that you use the key-range partitioning. The key can be based on a column or a set of columns that are distributed across partitions evenly and across the compute nodes of the Amazon Redshift cluster.
When the key column that you select for the source partitioning is same as the distribution key of the Amazon Redshift cluster, the Secure Agent reads the data faster.
Amazon Redshift Connector supports the following partitions:
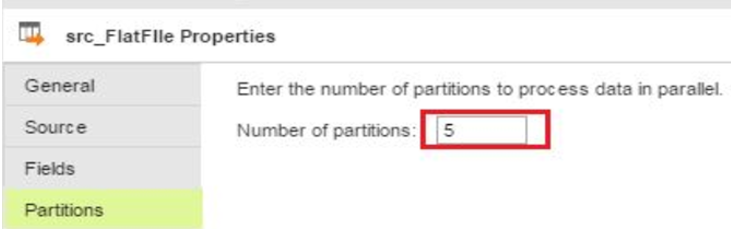
Pass-through partitioning
: You can specify the number of partitions when you read flat file sources.
The following image shows an example of the
Pass-Through Partitioning
tab:
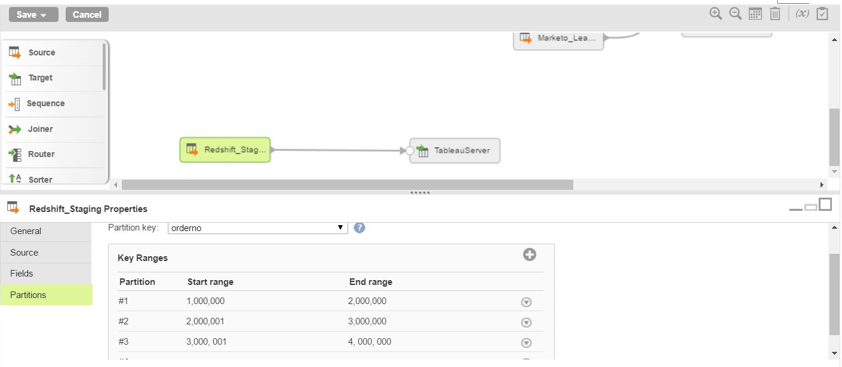
Key-Range partitioning
: With key-range partitioning, the number of source partitions you need to create depends on the Amazon Redshift cluster workload management concurrency setting. By default, the value is 5. If the value is set to the default value, you must create five partitions on the source side.