The ODBC and JDBC drivers are best for querying and to perform read or write operations for a lesser amount of data. However, for a native application specific integration, you need a faster performance.
Informatica offers native connectors that supports optimized integrations to read data from a non- Amazon Redshift source faster.
Use the following recommendations when you read large volumes of source data:
On cloud, use the
Bulk API
option.
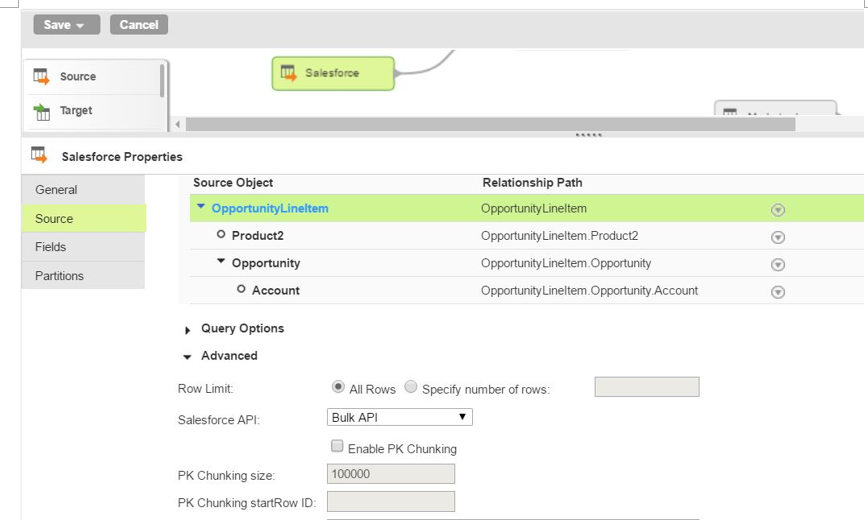
The following image shows the Bulk API option when you read data from a Salesforce source:
If you want to read data from a single table, use the select statements with an
ORDER BY
or
GROUP BY
clause. You can optimize the time to read bulk data by adding indexes.
Use the SQL filter options to reduce the volume of data.
If you read data by joining multiple source tables in one Source Qualifier, you can improve the performance by optimizing the query with optimizing hints. The database administrator can create optimizer hints to inform the database on how to execute the query for a set of source tables. The query used to read data appears in the session log. The database administrator can analyze the query, create optimizer hints, and indexes for the source tables.