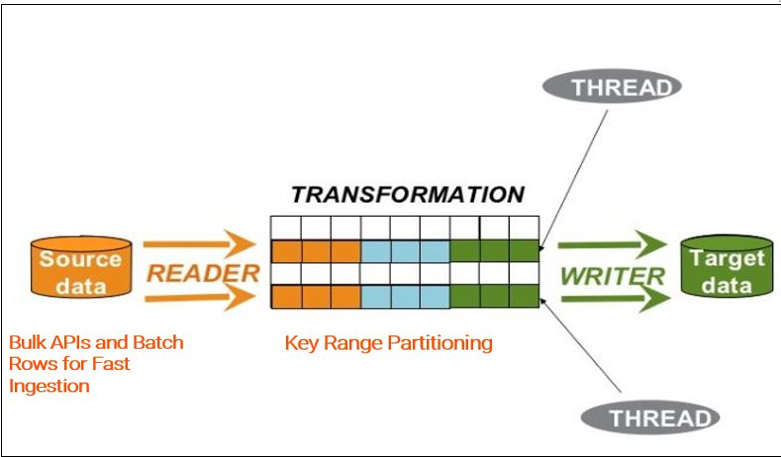
On cloud and PowerCenter, you can partition the data to optimize the performance and allows optimum utilization of the system resources.
Apart from configuring the DTM buffer size, buffer block size, and batch size to optimize the performance, you can further improve the performance at the external sources, targets, or transformations level. External source or target connection performance is more dependent on external application optimization, network latency, DTM buffer block size, and commit interval. The transformation level optimization is related to I/O operations and partitions, or partitions points.
Informatica supports creation of parallel data pipelines with a thread-based architecture. The partitioning of data across the parallel data pipelines is handled automatically. The partitioning option executes optimal parallel mapping by dividing the data processing into subsets, which runs in parallel and are spread among available CPUs in a multiprocessor system.
Unlike the approaches that require manual data partitioning, the partitioning option automatically guarantees data integrity because Informatica provides parallel engine that dynamically realigns data partitions for set-oriented transformations. Configurable mapping options, such as error handling, recovery strategy, memory allocation, and logging makes the mapping easier to gather statistics used to maximize the performance. By enabling the hardware and software to scale for handling large volumes of data and users, the partitioning option improves the performance and productivity.
Amazon Redshift Connector supports pass-through and key-range partitioning. PowerExchange for Amazon Redshift for PowerCenter supports pass-through partitioning.
Informatica partitioning for Amazon Redshift follows the principle of serializable isolation. This enable you to run two concurrently transactions T1 and T2, giving the same results as at least one of the following:
T1 and T2 run serially in that order.
T2 and T1 run serially in that order.
The following image shows how the source data are partitioned and loaded to the target: