Mass Ingestion Task to Upload Data into Amazon S3 or Amazon Redshift
Mass Ingestion Task to Upload Data into Amazon S3 or Amazon Redshift
On cloud, as more and more companies wants to create data lakes in addition to the data warehouse, it has become a common requirement to upload data from various sources to a data lake, such as a data lake on Amazon S3.
Once the data is available in the data lake, you can process data and load the data in the data warehouse. In the data warehouse, the data are stored in a structured way that is more suitable for conventional analytics and data scientists can use the data lake for huge data analyses.
In addition to the data that is in applications, such as ERP, CRM, or database, nowadays most of the companies store data in various file formats, such as Avro, CSV, ORC, JSON, and Parquet. It is common to have large amount of files that are generated or received from the third-parties or other applications on a regular basis. You typically want ongoing loads set up for such files that can provide Managed File Transfer (MFT) features as data are loaded to the data lake.
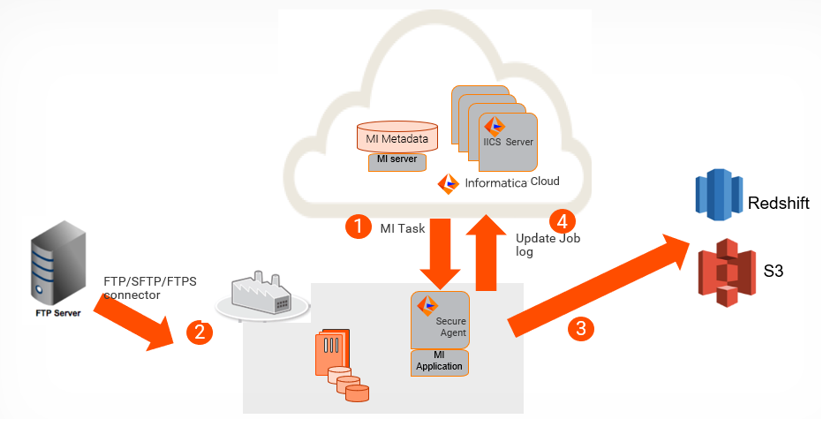
On cloud, you can use mass ingestion tasks on Informatica Intelligent Cloud Services to upload a large number of files of any file type between on-premises and cloud repositories, and track or monitor file transfers. You can upload files from any file container, such as local folders, FTP folders, or Amazon S3 bucket using a name or expression pattern. You can also upload files to Amazon S3 or Amazon Redshift staging location directly at once, instead of moving single row of data separately. When you create a mass ingestion task to upload files, you can perform the Managed File Transfer (MFT) features, such as encryption, compression, override, and rename.
The following image illustrates the mass ingestion task to upload data to Amazon S3 or Amazon Redshift staging location: