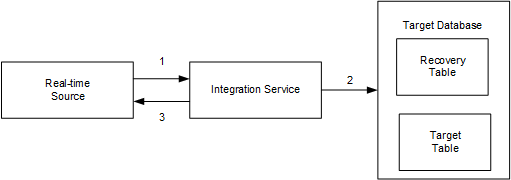
The following image shows how the Integration Service processes messages using the recovery table:
The Integration Service completes the following tasks to process messages using recovery tables:
The Integration Service reads one message at a time until the flush latency is met.
The Integration Service writes the message IDs, commit numbers, and the transformation states to the recovery table on the target database and writes the messages to the target simultaneously.
When the target commits the messages, the Integration Service sends an acknowledgement to the real-time source to confirm that all messages were processed and written to the target.
The Integration Service continues to read messages from the source.
If the session has multiple partitions, the tasks apply to each partition.