La tabla de destino Write_GoodMatches_Customer recibe filas desde el grupo Salida estándar. La tabla recibe los registros únicos y los registros que son duplicados. Estos registros no requieren de revisión manual.
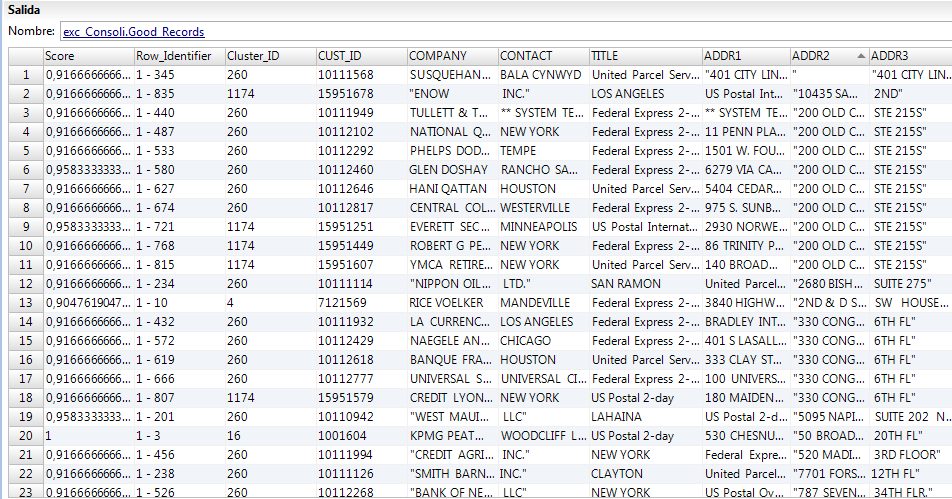
La siguiente figura muestra los registros de la salida estándar que la transformación de excepción devuelve:
El registro contiene los siguientes campos:
Puntuación
Puntuación de coincidencia que indica el grado de similitud entre un registro y otro registro del clúster. Los registros con una puntuación de coincidencia de uno son registros duplicados que no necesitan revisarse. Un clúster en el que cualquier registro tiene una puntuación de coincidencia por debajo del umbral inferior no es un clúster duplicado.
Row_Identifier
Un número de fila que identifica de forma exclusiva cada fila en la tabla. Para este ejemplo, el identificador de fila contiene el ID de cliente.
Cluster_ID
Un identificador exclusivo para un clúster. Cada registro en un clúster recibe el mismo ID de clúster. Los primeros cuatro registros de los datos de salida de ejemplo son únicos. Cada registro tiene un ID de clúster único. Las filas entre la cinco y la nueve pertenecen al clúster cinco. Cada registro en este clúster es un duplicado registro debido a las similitudes en los campos de dirección.
Campos de datos de origen
El grupo de la tabla de salida estándar también recibe todos los campos de datos de origen.