Attracting, acquiring, and retaining customers are essential for a company’s success. In order to perform these activities effectively, an organization must maintain accurate, complete, and timely customer entity and relationship data. The views associated with that data must also be maintained.
Maintaining unified views of multiple entities—such as product, supplier, employee, and contract, and the relationships between them—across disparate data silos can be challenging. There are multiple reasons for this:
Master data (reference and relationship data) is created and locked in multiple silos (applications, data warehouses, data marts, external sources, or channels), which often contain duplicate or conflicting information.
Different pieces of master data are owned by different parts of the business, isolated by organizational boundaries.
Many of these data sources have proprietary fixed data models that present barriers to unification.
It is difficult to govern changes to distributed master data.
Legacy data hubs, such as a Customer Information File (CIF) are difficult to extend, but they cannot be abandoned until replacement systems are in place.
Significant data quality issues and conflicting data and semantics (metadata) exist within and across data sources.
Master data is fairly dynamic and changes quickly.
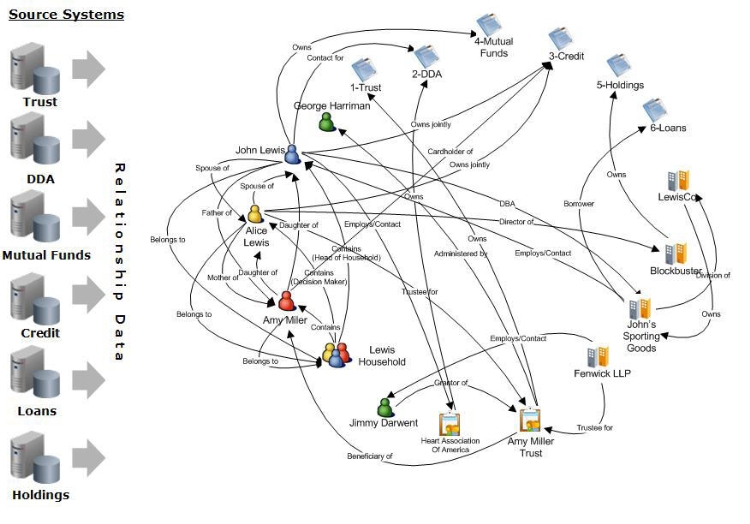
In the following scenario, the Lewis family has many different kinds of relationships with many different kinds of individuals and other types of entities, such as trusts. The information is housed in six source systems. The following figure depicts the discoverable relationships within the information.
Trying to sort out John Lewis’ sphere of influence from this data can be daunting, because it is not filtered or organized in a way that all of John’s relationships are immediately obvious and easily retrieved.