A tabela de destino Write_GoodMatches_Customer recebe linhas do grupo de Saída Padrão. A tabela recebe registros exclusivos e recebe registros que são duplicados. Esses registros não exigem revisão manual.
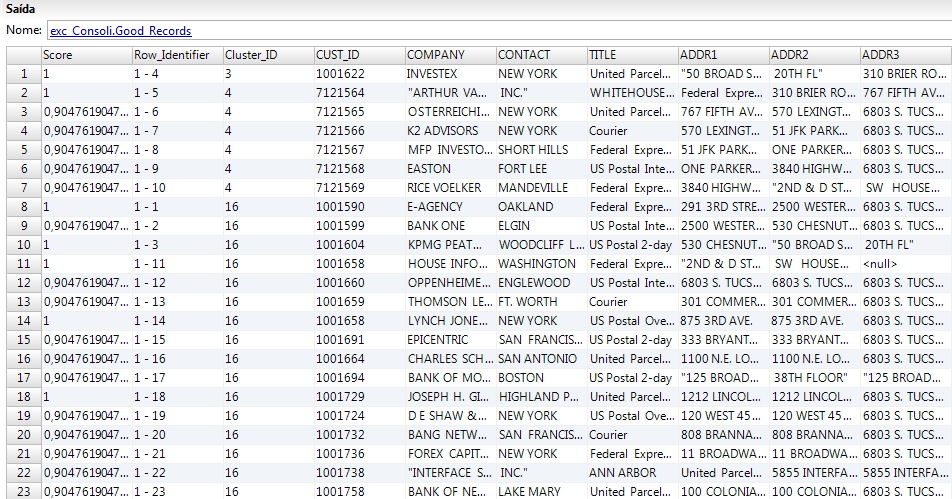
A figura a seguir mostra os registros de Saída Padrão que a transformação de Exceção retorna:
O registro contém os seguintes campos:
Pontuação
Pontuação de correspondência que indica o grau de semelhança entre um registro e outro registro no cluster. Os registros com uma pontuação de correspondência de um são registros duplicados que não precisam de revisão. Um cluster no qual qualquer registro tem uma pontuação de correspondência abaixo do limite inferior não é uma duplicata de cluster.
Row_Identifier
Um número de linha que identifica exclusivamente cada linha na tabela. Por exemplo, o identificador de linha contém o ID de cliente.
ID de Cluster
Um identificador exclusivo para um cluster. Cada registro em um cluster recebe o mesmo ID de cluster. Os quatro primeiros registros do exemplo de dados de saída são exclusivos. Cada registro tem uma ID de cluster exclusiva. As linhas de cinco a nove pertencem ao cluster cinco. Cada registro no cluster é um registro duplicado devido às similaridades dos campos de endereço.
Campos de Dados de Origem
O grupo de tabela Saída Padrão também recebe todos os campos de dados de origem.