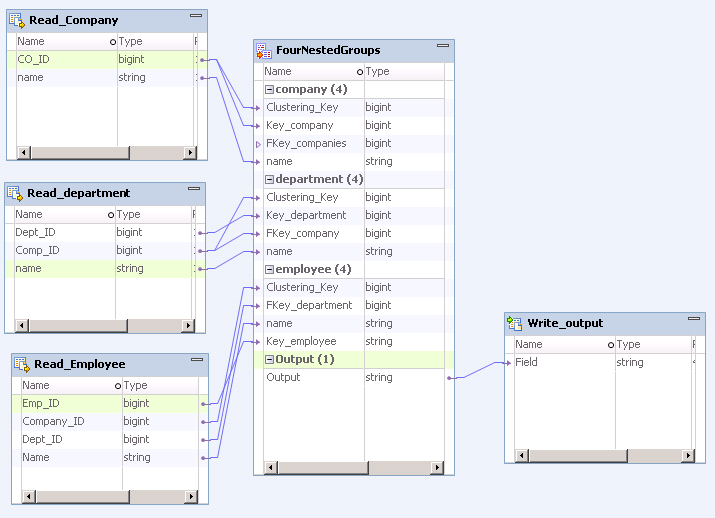
When you create a relational to hierarchical Data Processor transformation with multiple groups in the Hive environment, enable input data partitioning to ensure that data for each row processes correctly. The Data Integration System partitions the input rows according to a port that functions as a partitioning key named the Clustering_Key.
To partition input data to a Data Processor transformation in a mapping, select the transformation in the mapping, and in the
Advanced
tab of the
Properties
view, select to enable partitioning. When you enable partitioning, the Developer creates a Clustering_Key port in the Data Processor transformation for each input group.
Each input group must use the same foreign key to the input root group to help partitioning. To sort data according to a key, connect the selected foreign key relational input port of each Data object to the relevant Clustering_Key port in the Data Processor transformation. The Data Integration Service uses the Clustering_Key to partition and process the data.
You must use the same key in all of the relational input groups. If needed, you can use a Joiner transformation to add the key to a relational input group that does not have that key.
The following image shows a mapping with the foreign key Company_ID in the relational input groups linked to the Clustering_Key ports in the Data Processor transformation: