In the [RUN] and [INDIRECT] sections of the configuration file, specify runtime parameters.
In the [RUN] section, you can enter the following generic and direct path unload parameters:
asm_debug
Set this parameter to true only at the request of Informatica Global Customer Support. For Oracle sources in an Automatic Storage Management (ASM) environment, a value of true causes Fast Clone to print an ASM debug log to the asm_debug.log file.
Default value: false
This parameter is not available in the Fast Clone Console. Edit the cloning configuration file to add this parameter manually.
big_raw_device_offset_mul
For Oracle sources that use raw devices on AIX, the number of offset blocks to skip from the beginning of a DF_LGDSK raw device when the
calc_raw_device_offset
parameter is set to true. You can specify the size of a single offset block in the
raw_device_offset
parameter. To get the total number of bytes that Fast Clone skips on DF_LGDSK raw devices, multiply the
raw_device_offset
value by the
big_raw_device_offset_mul
parameter value.
Valid values: 1 through 64
Default value: 32
binary_length_prefix
For Teradata targets, indicates whether to unload source data in binary format. Each record in binary format can include a 2-byte field that indicates the total length of the record, some optional bytes for null values, and the data.
For Vertica targets, indicates whether to unload source data in the NATIVE VARCHAR or text format. If you set this parameter to true, Fast Clone adds the NATIVE VARCHAR keyword to the COPY or LCOPY command in the output SQL load script. The database server converts CHAR or VARCHAR fields in the data files to Vertica datatypes when loading data. If you set this parameter to false, Fast Clone loads source data in text format with delimiters. Valid values are true and false.
Default value: false
binary_length_prefix_indicators
For Teradata targets, if you set the
binary_length_prefix
parameter to true, indicates whether to set the indicator bits in the binary output for columns that contain null values. Valid values are:
true
. Set the indicator bits to 1 for null values.
false
. Do not set indicator bits.
Default value: false
This parameter is not available in the Fast Clone Console. To use the parameter, manually enter it in the cloning configuration file.
binary_length_prefix_little_endian
If you set the
binary_length_prefix
parameter to true, indicates whether to use LITTLE ENDIAN or BIG ENDIAN for the binary output. For Teradata targets, this parameter determines the format of the integer that specifies the length of records and fields in the binary files. Valid values are:
true
. The binary output uses the LITTLE ENDIAN format.
false
. The binary output uses the BIG ENDIAN format.
Default value: true
blocks_per_lob_read
Specifies the number of Oracle data blocks that Fast Clone fetches from LOB columns per read operation.
Change this parameter only if Fast Clone unload performance is slow. The value of this parameter depends on the extent size for locally managed tablespaces and the table-specific extent sizes for dictionary-managed tablespaces.
Valid values: 1 through 128
Default value: 4
blocks_per_read
Specifies the number of Oracle data blocks that Fast Clone fetches per read operation.
Change this parameter only if Fast Clone unload performance is slow. The value of this parameter depends on the extent size for locally managed tablespaces and the table-specific extent sizes for dictionary-managed tablespaces.
Valid values: 1 through 1024
Default value: 32
calc_raw_device_offset
Indicates whether Fast Clone skips the offset block in raw devices. Valid values are:
true
. Skip the offset block in raw devices.
false
. Read data from the beginning of the raw device.
To get the total number of bytes that Fast Clone skips in a DF_LGDSK raw device, multiply the
raw_device_offset
value by the
big_raw_device_offset_mul
parameter value.
Default value: true
characterset
For Teradata targets, indicates whether to convert the source character data to UTF-8. By default, Fast Clone preserves the source database encoding. Valid values are:
NONE
. Preserve the source character set.
UTF8
. Unload the data in the UTF-8 format.
Default value: NONE
checkpoint_each_x_tables
Specifies the number of tables from which Fast Clone unloads data before taking a checkpoint.
Valid values: 0 through 100000
Default value: 0. With this default, Fast Clone takes a checkpoint only before it starts unloading source data.
column_list_clause_byname_filtering
Indicates whether Fast Clone unloads columns in the custom order that is specified in the
TABLE_ID
_COLUMN_BIT_MASK parameter in the [COLUMN_BIT_MASK] section of the configuration file. Valid values are:
true
. Fast Clone unloads columns in the custom order that is specified in the
TABLE_ID
_COLUMN_BIT_MASK parameter.
false
. Fast Clone unloads columns in the order in which the columns appear in the source database.
Default value: false
column_separator
Specifies a character or character sequence that Fast Clone uses to separate columns in the output data files. Specify a character or character sequence that does not appear in the source data. Otherwise, the target load utility cannot correctly parse the data files. For more information, see
Selecting Column and Row Separator and Enclosure Character Using Sampling.
You can specify a column separator that uses the \x
hh
escape sequence in hexadecimal notation.
Also, you can use the following non-printable ASCII characters as column separators:
\a (alert)
\b (backspace)
\n (new line)
\r (carriage return)
\t (horizontal tab)
\v (vertical tab)
If you use non-printable ASCII characters, ensure that the target load utility supports these characters as separators. For more information, see the target database documentation.
Default value: semicolon (;)
compress_network_traffic
Indicates whether to compress network traffic. Valid values are:
true
. Compress network traffic.
false
. Do not compress network traffic.
Default value: false
compress_on_the_fly
Indicates whether to compress the output data files during unload processing to reduce the file sizes. Valid values are:
true
. Compress the output data files. The compression method is specified in the
compression_type
parameter.
false
. Do not compress the output data files.
Default value: false
compression_level
Specifies the compression level for the GZIP compression method. Higher values result in faster compression and a lower compression ratio. Lower values result in slower compression and a higher compression ratio. For Fast Clone to use this parameter, the
compression_type
parameter must be set to GZIP and the
compress_on_the_fly
parameter must be set to true.
Valid values: 1 through 9
Default value: 1
compression_type
If you set the
compress_on_the_fly
parameter to true, specifies the compression method that Fast Clone uses to compress the output data files. Valid values are:
GZIP
. Provides a better compression ratio but is slower. You can set the GZIP compression level in the compression_level parameter.
QZIP
. Provides a lower compression ratio but is faster.
Default value: GZIP
consistent_lock_on_table_set
If you use the direct path unload method and set the
dirty
parameter to false, indicates whether to lock all of the selected tables in a table set before unloading the source data. Valid values are:
true
. Fast Clone locks all of the selected source tables in a table set before unloading the source data. Fast Clone unlocks these tables after unloading data from all of them. Enter this value to get consistent point-in-time data across the selected source tables.
false
. Fast Clone holds a lock on each source table only while unloading data from the table.
Default value: false
control_file_name_base
Specifies the naming pattern that Fast Clone uses to generate names for control files, log files, and SQL scripts. You can use the following variables:
%&schema&% - Represents a default schema name for the user that Fast Clone uses to connect to the source database.
%&source_schema&% - Represents a source schema name.
%&target_schema&% - Represents a target schema name.
%&table&% - Represents a table name.
%&table_counter&% - Represents a sequence number of a table.
%&partition&% - Represents a partition name.
The partition variable is required if you specify partitions in the [SOURCE_TABLES] or [SOURCE_INDIRECT_TABLES] sections of the configuration file.
%&counter&% - Represents the sequence number of a control file for a table. This variable value is always 1.
parameter, Fast Clone uses the table name as the name for control files, log files, and SQL scripts.
convert_ascii_to_ebcidic
Indicates whether Fast Clone converts source data to the EBCDIC encoding when unloading data to output data files and pipes. Valid values are:
true
. Convert source data to the EBCDIC encoding.
false
. Preserve the original encoding.
Default value: false
convert_numbers_to_comp3_fl_8b
Indicates whether to write numeric data to the output data files as COMP-3 values. Valid values are:
true
. Convert numeric data to COMP-3 in the output data files. Use this value if you need to read the output file with COBOL or another language that has built-in COMP-3 support.
false
. Preserve the original numeric format.
Default value: false
convert_numbers_to_comp3_implied_decimal
The position of the decimal point in the COMP-3 format.
Valid values: 0 through 14
Default value: 0
convert_utf16_clobs_to_utf8
Indicates whether Fast Clone converts CLOB data from UTF-16 to UTF-8 encoding in the output data files. Valid values are:
true
. Convert source character data in CLOB columns from UTF-16 to UTF-8 encoding.
false
. Do not convert source character data in CLOB columns. If you do not use UTF-16 encoding for the source data, set this parameter to false to avoid the overhead of character set conversion.
Default value: false
convert_utf16_nchars_to_utf8
Indicates whether Fast Clone converts NCHAR and NVARCHAR2 data from UTF-16 to UTF-8 encoding in the output data files. Valid values are:
true
. Convert source character data in NCHAR and NVARCHAR2 columns from UTF-16 to UTF-8 encoding.
false
. Do not convert source character data in NCHAR and NVARCHAR2 columns.
If you do not use UTF-16 encoding for the source data, set this parameter to false to avoid the overhead of character set conversion. To use the parameter, you must manually enter it at the command line or in the cloning configuration file. You cannot enter it in the Fast Clone Console.
Default value: false
convert_utf16_nclobs_to_utf8
Indicates whether Fast Clone converts NCLOB data from UTF-16 to UTF-8 encoding in the output data files. Valid values are:
true
. Convert source character data in NCLOB columns from UTF-16 to UTF-8 encoding.
false
. Do not convert source character data in NCLOB columns.
If you do not use UTF-16 encoding for the source data, set this parameter to false to avoid the overhead of character set conversion. To use the parameter, you must manually enter it at the command line or in the cloning configuration file. You cannot enter it in the Fast Clone Console.
Default value: false
create_external_table_log_file
For Oracle targets, if you create an SQL script for creating external tables based on the output files, indicates whether to log messages related to this processing to a log file. Valid values are:
true
. The Oracle external table utility logs messages to a log file when accessing data in the output data files. Ensure that the
create_external_table_script
parameter is also set to true.
false
. The Oracle external table utility does not log these messages.
. Add the partition name to the external table name in the following format:
table
_
partition
false
. Do not add the partition name to the external table name.
Default value: false
create_external_table_script
For Oracle targets, indicates whether Fast Clone generates an SQL script to create Oracle external tables based on the output data files. Valid values are:
true
. Create an SQL script to create Oracle external tables based on the output data files.
false
. Do not create an SQL script to create Oracle external tables based on the output data files.
Default value: false
create_load_input_only
Indicates whether Fast Clone creates the load script and control files but skips unloading data from the source database. Valid values are:
true
. Create a load script and the control files. Do not unload data from the source database.
false
. Create a load script and the control files. Unload data from the source database.
Fast Clone does not generate load scripts and control files for flat file, Hadoop, and Hive targets.
Default value: false
create_output_pipe_instead_of_file
Indicates whether Fast Clone creates pipes in the output directory and writes the output data to these pipes. Valid values are:
true
. Fast Clone creates pipes in the output directory.
false
. Fast Clone does not create pipes in the output directory. Use this value to unload data to output data files or to the pipes that you manually created.
Default value: false
date_format
Specifies the date format to use in output files.
The following table specifies the datetime format elements that Fast Clone supports with the direct path unload method:
Format Element
Description
DD
Day of month
FF
number
Number of fractional seconds
Valid values: 1 through 9
HH
Hour of day in 12-hour format
HH24
Hour of day in 24-hour format
MI
Minutes
MM
Month
SS
Seconds
YY
Last 2 digits of the year
YYYY
4-digit year
For example, the following format values are valid:
YYYY-MM-DD HH24:MI:SS
DDMMYYYY
YYYY-MM-DD
HH24:MI:SS
Default value: YYYY-MM-DD HH24:MI:SS
dbsync_config_xml
Specifies the path and file name for the Data Replication configuration file that can be in XML or SQLite format. The path is relative to the DBSYNC_HOME directory.
If you use a Data Replication configuration in SQLite format, do not copy or move the configuration files from the default
DataReplication_installation
/configs directory to another location.
Default value: config.xml
dbsync_config_xsd
Specifies the path and file name for the Data Replication configuration schema .XSD file. The path is relative to the DBSYNC_HOME directory.
Default value: config.xsd
dbsync_integration
Indicates whether Fast Clone integrates with Informatica Data Replication. Also, when integration is enabled, determines whether Fast Clone allows user sessions that are connected to the source tables to complete processing before locking the tables. Valid values are:
false
. Do not integrate Fast Clone with Data Replication.
lock
. Integrate Fast Clone with Data Replication. Fast Clone waits for all user sessions that are connected to the source tables to complete processing and close before locking the tables for unload processing.
lock_disconnect
. Integrate Fast Clone with Data Replication. Fast Clone forces all user sessions that are connected to the source tables to disconnect and then locks the tables for unload processing.
Default value: false
dbsync_integration_by_direct
If you enable integration with Data Replication, indicates whether to unload data from the source database with the direct path unload method. Valid values are:
true
. Use the direct path unload method.
false
. Use the conventional path unload method.
Default value: true
dbsync_integration_update_scn
Indicates whether to update the Data Replication configuration file with the SCN for each mapped table after Fast Clone unloads the source data. Valid values are true and false.
Set this parameter to true if you plan to use Data Replication to replicate change data and use Fast Clone to perform initial materialization of the replication target tables.
Default value: true
decimal_separator
Specifies the decimal separator that Fast Clone uses in decimal numbers in unloaded data.
Default value: period (.)
default_long_raw_is_hex
For Oracle targets, indicates whether to unload BLOB and LONG RAW source data in hexadecimal format. Set this parameter to true to unload data with these datatypes in hexadecimal format. For other target types, set this parameter to false to avoid generating incorrect control files.
Default value: false
destination_loader_to_use
For Teradata and Vertica targets, specifies the load utility or command that Fast Clone uses to load data to the target. Enter a load utility or command that Fast Clone supports.
Valid values for Teradata loaders:
teradata_fast_load
. Use the Teradata FastLoad utility, or use the TPT Load Operator if using Teradata Parallel Transporter (TPT).
teradata_multi_load
. Use the Teradata MultiLoad utility, or use the TPT Update Operator if using Teradata Parallel Transporter (TPT).
teradata_parallel_dpump
. Use the TPT Stream Operator. In this case, you must use Teradata Parallel Transporter (TPT).
Valid values for Vertica loaders:
isql_copy
. Use this command to load data from the data files that are located on the target database server.
isql_lcopy
. Use this command to load data from the data files that are located on the system where you run the target load utility.
Default value: teradata_fast_load
direct_data_stream
For Greenplum, Netezza, Teradata, and Vertica targets, indicates whether Fast Clone uses DataStreamer to load data to the target database.
For Greenplum targets, DataStreamer uses the Greenplum gpfdist utility.
For Netezza targets, Fast Clone unloads data to the named pipes that represent the Netezza external tables. DataStreamer uses bulk Insert to load data from the external tables to the corresponding target tables.
For Teradata targets, DataStreamer send the unloaded data directly to the Teradata Parallel Data Pump, FastLoad, or MultiLoad utility for loading to the target.
For Vertica targets, DataStreamer uses the COPY command on the server side and the LCOPY command on the client side to send the unloaded data directly to Vertica targets.
Valid values are:
true
. Use DataStreamer to load data to the target database.
false
. Do not use DataStreamer to load data to the target database.
Default value: false
direct_select_from_sys
Indicates whether Fast Clone uses SYS-owned dictionary tables, such as sys.obj$ and sys.tab$, to get extent boundaries. Valid values are:
true
. Use SYS-owned dictionary tables to get extent boundaries.
false
. Use dba_extents and dba_segments views to get extent boundaries.
If you set this parameter to false for Oracle sources that use locally managed tablespaces, retrieval of extent information from the dba_extents view is slow, especially if the dictionary is partially analyzed and the optimizer mode is not RULE. In this situation, Informatica recommends that you set this parameter to true and grant the SELECT ANY DICTIONARY permission to the user.
Default value: false
dirty
Indicates whether to lock the tables that are unloaded with the direct path unload method to perform consistent read operations. Valid values are:
true
. Do not lock the tables before unloading the source data. Use this option if you want to bypass the Oracle consistency mechanism. However, block-level consistency is preserved, because block
I/O
operations are atomic.
false
. Lock the tables exclusively before unloading the source data.
Default value: true
disable_linux_cache_bypass
For Linux operating systems, indicates whether to use direct
I/O
mode to read Oracle data files. In direct
I/O
mode, Fast Clone bypasses operating system caching and reads data directly from disk. Set this parameter to true to use direct
I/O
mode.
Default value: false
enclose_dates
Indicates whether to use the character that is specified by the
optionally_enclosed_by
parameter to enclose, or delimit, dates. Set this parameter to true to use this character.
Default value: false
enclose_numbers
Indicates whether to use the character that is specified by the
optionally_enclosed_by
parameter to enclose, or delimit, numbers. Set this parameter to true to use this character.
Default value: false
encrypt_database_passwords
Indicates whether the password that is specified by the
dba_password
parameter in the [SOURCE] section of the configuration file is encrypted. Valid values are:
true
. The password is encrypted.
false
. The password is not encrypted.
Default value: true
escape_enclosure
Specifies an escape character that Fast Clone inserts before the character that is specified in the
optionally_enclosed_by
parameter when the character appears in text columns. If you define this parameter, Fast Clone truncates the
optionally_enclosed_by
value to a single character.
Default value: No default is provided.
explicitly_flush_buffer_cache
Indicates whether Fast Clone clears all data from the buffer cache of the Oracle source database before unloading the data with the direct path unload method. Valid values are:
true
. Fast Clone clears all data from the buffer cache by executing the following command on the Oracle source database:
ALTER SYSTEM FLUSH BUFFER_CACHE;
false
. Fast Clone does not clear data from the buffer cache.
Default value: false
export_all_tables_for_owner
Indicates whether to unload data from all tables in the specified schema or from only the tables that you specify. If you choose to unload data from all tables in the schema, indicates whether to use the direct path unload or conventional path unload method.
Valid values:
NONE
. Fast Clone unloads data from only the source tables that you specified in the [SOURCE_TABLES] or [SOURCE_INDIRECT_TABLES] section of the configuration file. You must specify at least one table in one of these sections.
AUTO
. Fast Clone unloads data from all tables in the specified schema by using the direct path unload method if possible. If Fast Clone cannot use the direct path unload method, Fast Clone unloads data by using the conventional path unload method.
ALL_DIRECT
. Fast Clone unloads all tables in the specified schema by the using direct path unload method.
ALL_CONVENTIONAL
. Fast Clone unloads all tables in the specified schema by using the conventional path unload.
Default value: NONE
export_binary_to_separate_files
Indicates whether to write data from BLOB, CLOB, NCLOB, LONG, and LONG RAW source columns to separate files. In the regular data files, Fast Clone includes the file name instead of the source value. Specify true to write data from columns with these datatypes to separate files. For Hive targets, Fast Clone always uses the parameter value of false.
Default value: false
If you use DataStreamer to load source data to Netezza targets, set this parameter to false.
fixed_size_characters_by_col_definition
Indicates whether to unload data from character columns in fixed-length format. The fixed length is determined by the column length. If a text value is shorter than the column length, Fast Clone pads the column with spaces up to the full column length. Specify true to unload character data in fixed-length format.
Default value: false
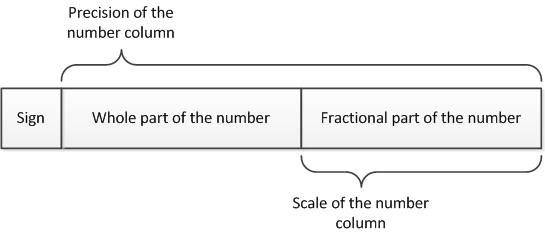
fixed_size_number_by_col_definition
Indicates whether to unload data from NUMBER columns in the fixed-length format. Specify true to unload character data in fixed-length format. The fixed length is defined by the precision of the NUMBER column, without a decimal separator. If a number is shorter than this length, Fast Clone pads the value with zeroes. The following image shows the fixed-length format of a NUMBER column:
For example, when using fixed-length format, Fast Clone unloads the value 123.45 from the NUMBER(10,5) column as +0012345000.
Default value: false
global_date_nvl
Specifies a date value that Fast Clone inserts instead of null values in DATE columns.
You can specify a date value in any format. However, for consistency, use the format that is specified by the
date_format
parameter.
Default value: No default is provided.
greenplum_gpfdist_connection_timeout
For Greenplum targets, specifies the time interval, in seconds, that Fast Clone waits for a response from Greenplum when opening a connection to the target. If this interval elapses without a response, Fast Clone times out.
Valid values: 0 through 1000000
Default value: 55
greenplum_gpfdist_current_hostname
For Greenplum targets, specifies the host name or IP address of the system where you run the Fast Clone instance that starts the gpfdist utility for loading data.
Default value: localhost
greenplum_gpfdist_listen_hostname
For Greenplum targets, specifies the IP addresses on which the gpfdist utility listens for incoming requests. Use 0.0.0.0 to have the gpfdist utility listen for requests from all interfaces.
Default value: No default is provided.
greenplum_gpfdist_listen_port
For Greenplum targets, specifies the listener port for the gpfdist utility. The Greenplum target uses this port to submit requests to the gpfdist utility to load data.
Valid values: 0 through 65536
Default value: 8000
ip_instead_of_file
If the
use_ip_instead_of_file
parameter is set to true, specifies the IP address or host name and the port number of the Fast Clone Server to which Fast Clone sends output files. Use the following format for the value:
host_or_ipaddress
:
port
Default value: No default is provided.
limit_result_set
Specifies the maximum number of rows that Fast Clone unloads from each table. Set this parameter to -1 to unload all rows from a table.
Valid values: -1 through 1073741823
Default value: -1
load_data_to_same_partition_as_source
For Oracle targets, indicates whether SQL*Loader loads data to a table partition that has the same name as the corresponding source table partition. Specify true to load data from a source table partition to a target table partition of the same name.
Default value: false
load_script_base_name
Specifies the file name of the load script. On Windows, Fast Clone generates load script files with the .cmd extension. On Linux and UNIX, Fast Clone generates load script files with the .sh extension.
Default value: The source schema owner name that is specified by the
owner
parameter in the [SOURCE] section of the cloning configuration file.
local_time_zone
For Teradata targets, specifies the local time zone to use for unloading data from TIMESTAMP WITH LOCAL TIME ZONE columns. Specify the time zone as an offset from the Oracle database time zone:
"+/-
HH
:
MM
"
The
HH
variable is a two-digit number from -13 to +13. The
MM
variable is a two-digit number from 0 to 59.
For example, enter "+08:00".
Default value: No default is provided.
log
Indicates whether Fast Clone produces an extended log. Set this parameter to true only at the request of Informatica Global Customer Support.
Default value: false
mb_per_file
Defines the maximum amount of data, in megabytes, that a single output data file (.dat file) can contain.
Valid values: -1 through 65530
Default value: -1. With this default value, Fast Clone does not enforce a limit on the size of the output data files.
netezza_control_chars_enabled
If you use DataStreamer to load data to a Netezza target, specifies the value of the EscapeChar option for the Netezza external tables. This option indicates whether the control characters, such as delimiter and backslash characters, are escaped in the data fields of the external tables. The Netezza external tables use a backslash as an escape character.
Default value: true
netezza_error_log_directory
If you use DataStreamer to load data to a Netezza target, specifies the directory in which DataStreamer creates the following Netezza log files:
table_name
.
schema_name
.nzlog. This log file includes load statistics and diagnostic messages that the Netezza ODBC driver issues when loading data to the target tables from the corresponding external tables.
table_name
.
schema_name
.nzbad. This log file includes the external table rows that DataStreamer could not load to the corresponding target table.
Default value: The output directory
netezza_pipe_directory
If you use DataStreamer to load data to a Netezza target, specifies the directory in which Fast Clone creates named pipes that represent Netezza external tables.
On Windows, DataStreamer ignores this parameter because the named pipes are created in the named pipe directory that is mounted under the special path \\.\pipe\.
Default value: The output directory
netezza_quoted_value
If you use DataStreamer to load data to a Netezza target, specifies the value of the QuotedValue option for the Netezza external tables. DataStreamer requires this option to build correct Insert statements when loading data to the target tables from the corresponding external tables. Options are:
single
. Indicates that the data values in the external tables are enclosed with single quotation marks.
double
. Indicates that the data values in the external tables are enclosed with double quotation marks.
no
. Indicates that the data values in the external tables are not quoted.
Ensure that the quotation character that you specify for the load operation matches the quotation character that you specify for the unload operation. For unload jobs, Fast Clone uses the quotation character that you specify in the
Enclosed by
field on the
Runtime Settings
tab >
Format Settings
view.
Default value: no
nvl_fixed_size_characters_by_space
For character columns that are unloaded in fixed-length format, indicates whether to replace null values with space characters. Specify true to replace nulls with spaces.
Default value: false
ocfs_direct_io
For Oracle sources in an Oracle RAC and Oracle Cluster File System (OCFS) environment on Linux or UNIX, indicates whether Fast Clone uses direct
I/O
mode to read Oracle data files. Direct
I/O
mode minimizes the effects of cache on reading data from Oracle data files. Set this parameter to true if the Oracle data files are located in an OCFS.
Default value: false
optionally_enclosed_by
Specifies the character or character sequence that Fast Clone uses to enclose character data in output data files. Specify a character or character sequence that does not appear in the source data. The target load utility cannot correctly parse the data files if the enclosure character is a source data value.
If you use the default value and the source columns contain double-quotation marks (") in the data, specify a different character or character string for this parameter or use the escape character in the
escape_enclosure
parameter to escape the double-quotation marks in the column data.
If you use the character that is defined by the
escape_enclosure
parameter to escape the
optionally_enclosed_by
value in the source data, Fast Clone truncates the
optionally_enclosed_by
value to a single character.
Default value: Double-quotation mark (")
outdir
Specifies the directory in which Fast Clone creates the output files. The output directory can be on a local file system or on a network mapped share, such as NFS or Samba. For Hive targets, specifies the location of flat files that store table data on the HDFS.
Default value: The FAST_READER_HOME environment variable value.
output_file_extension_base
Specifies the extension that Fast Clone uses for output data files. Fast Clone creates a data file for each source table from which data is unloaded.
Default value: dat
output_file_name_base
Specifies the naming pattern that Fast Clone uses to create the base name of the output data files. In the naming pattern, you can include the following variables:
%&schema&% - Represents a default schema name for the user that Fast Clone uses to connect to the source database.
%&source_schema&% - Represents a source schema name.
%&target_schema&% - Represents a target schema name.
%&table&% - Represents a table name.
%&table_counter&% - Represents a sequence number of a table.
%&partition&% - Represents a table partition name. This partition variable is required if you specify partitions in the [SOURCE_TABLES] or [SOURCE_INDIRECT_TABLES] sections of the configuration file.
%&counter&% - Represents a sequence number of a data file for a table. This counter variable is required if Fast Clone splits the output data files based on the
parameter, Fast Clone uses the table name as the name for output data files.
output_ocfs_direct_io
For Oracle sources in an Oracle RAC and Cluster File System (OCFS) environment on Linux or UNIX, indicates whether Fast Clone uses direct
I/O
mode to write output files. Direct
I/O
mode minimizes the effects of cache on writing the output files. Set this parameter to true if you configured Fast Clone to generate output files in an OCFS.
Default value: false
print_column_names
For flat file targets, indicates whether Fast Clone writes column names in the first row of the output data files. Specify true to write column names in the first row.
Default value: false
This parameter is available for all target types when the
unload_data_only
parameter is set to true.
raw_device_offset
The size of a single offset block, in bytes, in a raw device. Fast Clone skips the offset block if you set the
calc_raw_device_offset
parameter to true. To get the total number of bytes that Fast Clone skips on DF_LGDSK raw devices, multiply the
raw_device_offset
value by the
big_raw_device_offset_mul
parameter value.
Default value: 0 for Linux, 4096 for other operating systems
read_securefile_by_direct
For Oracle 11
g
and Oracle 12
c
sources, enables Fast Clone to unload data with the direct path unload method from columns that have SecureFile LOB datatypes. The
read_securefile_by_direct
parameter also enables Fast Clone to unload data with the direct path unload method for the extended NVARCHAR2, RAW, and VARCHAR2 datatypes that were introduced in Oracle 12
c
. Valid values are:
true
. Fast Clone reads SecureFile LOB and extended datatypes with the direct path unload method.
false
. Fast Clone reads SecureFile LOB and extended datatypes with the conventional path unload method.
Default value: true
record_separator
A character or character sequence that Fast Clone uses to separate table rows in the output data files. Specify a character or character sequence that does not appear in the source data. Otherwise, the target load utility cannot correctly parse the data files. For more information, see
Selecting Column and Row Separator and Enclosure Character Using Sampling.
You can specify a row separator that uses the \x
hh
escape sequence in hexadecimal notation.
Also, you can use the following non-printable ASCII characters:
\a (alert)
\b (backspace)
\n (new line)
\r (carriage return)
\t (horizontal tab)
\v (vertical tab)
If you use non-printable ASCII characters in row separators, ensure that the target load utility supports these separators. For more information, see target database documentation.
Default value: \n
replace_new_line_with_space
Indicates whether to replace new line (\n) character in unloaded data with space characters. Specify true if you use the new line character as the row separator in output files and the source character data includes new line characters. However, with a value of true, unload processing performance might be degraded.
Default value: false
right_pad_columns
Indicates whether to pad columns on the right with spaces when the length of a column value is less than the full length of the column. Specify true to enable padding.
Default value: false
show_increments_rows
The number of rows that Fast Clone unloads with the direct path unload method before writing updated progress information for the unload job to the system console or command prompt window.
Valid values: 10 through 10000000
Default value: 50000
skip_all_out_file_ops
If you use DataStreamer to stream data to Greenplum or Teradata targets, Fast Clone skips writing data to output files. If you do not use DataStreamer and need to troubleshoot unload jobs, you can set this parameter to true to write the data to output files.
Default value: The
direct_data_stream
parameter value.
skip_unreadable_block
Indicates whether Fast Clone skips blocks that it cannot read from Oracle files when unloading data with the direct path unload method. Valid values are:
true
. Fast Clone skips the unreadable blocks and continues unload processing.
false
. Fast Clone ends with an error.
Default value: true
split_files_by_row_count
The maximum number of rows that Fast Clone writes to an output data file. If Fast Clone needs to unload a greater number of rows from the source table, Fast Clone creates multiple output data files for the table. The file names have the following format:
table_name
_
file_number
.dat
Specify this parameter only if you use the direct path unload method.
For parallel unload processing, splitting output into multiple data files based on a number of rows is slower than splitting output based on a chunk size. This performance degradation occurs because of locks between the parallel threads.
Valid values: -1 through 1000000000
Default value: -1. With this default value, Fast Clone does not create multiple output data files based on row count.
suppress_trailing_nullcols
Indicates whether Fast Clone includes trailing columns that contain null values in the output data files. Valid values are:
true
. Do not include trailing columns that contain null values.
false
. Include trailing columns that contain null values.
Default value: true
If the
trailing_column_separator
parameter is set to false, Fast Cone always includes trailing null columns, regardless of the
suppress_trailing_nullcols
parameter setting.
If you use DataStreamer to load data to an Amazon Redshift, Greenplum, Netezza, Teradata, or Vertica target, set this parameter to false. If you create the configuration file in a text editor, set the suppress_trailing_nullcolls parameter to false.
For Teradata targets, indicates whether DataStreamer tries to use the TPT Update Operator if the TPT Load Operator fails to load source data to target tables. Valid values are:
true
. DataStreamer tries to use the TPT Update Operator if the TPT Load Operator returns an error.
false
. DataStreamer does not try to use the TPT Update Operator if the TPT Load Operator returns an error.
Default value: true
If you do not use DataStreamer, this parameter is ignored.
teradata_drop_rebuild_tables
For Teradata targets, indicates whether DataStreamer drops and re-creates tables in the target database before it loads the source data. Valid values are: true and false.
Default: false
teradata_load_sessions
For Teradata targets, specifies the number of sessions that the Teradata FastLoad or MultiLoad utility can open to load the source data to each target table.
Default value: 2
teradata_loader_to_use
For Teradata targets, the Teradata load utility that Fast Clone generated load scripts call to load source data to the target. Valid values are:
teradata_fast_load
. Use the FastLoad utility, or use the TPT Load Operator if using the Teradata Parallel Transporter (TPT).
teradata_multi_load
. Use the MultiLoad utility, or use the TPT Update Operator if using the Teradata Parallel Transporter (TPT).
teradata_parallel_dpump
. Use the TPT Stream Operator. In this case, you must use the Teradata Parallel Transporter (TPT).
Default value: teradata_fast_load
This parameter is deprecated. Use the
destination_loader_to_use
parameter instead.
threads_num
Specifies the maximum number of tables or table partitions that Fast Clone can unload in parallel with the direct path unload method.
Valid values: 1 through 64
Default value: 1
threads_per_segment_num
Specifies the maximum number of threads that Fast Clone can use to unload data from each table or table partition with the direct path unload method.
Fast Clone might use fewer threads. Fast Clone does not create a thread to unload a chunk of less than 100 data blocks.
Valid values: 1 through 64
Default value: 1
timestamp_format
Specifies the timestamp format in the output.
The following table specifies the datetime format elements that Fast Clone supports with the direct path unload method:
Format Element
Description
DD
Day of month
FF
number
Number of fractional seconds
Valid values: 1 through 9
HH
Hour of day in 12-hour format
HH24
Hour of day in 24-hour format
MI
Minutes
MM
Month
SS
Seconds
YY
Last 2 digits of the year
YYYY
4-digit year
For example:
YYYY-MM-DD HH24:MI:SS.FF6
YYYY-MM-DD HH24:MI:SS
DDMMYYYY
YYYY-MM-DD
HH24:MI:SS
For the conventional path unload method, Fast Clone supports all timestamp formats.
Default value: YYYY-MM-DD HH24:MI:SS.FF6
trailing_column_separator
Indicates whether to add a column separator after the last column value in each row in the output. Valid values are:
true
. Add a column separator after the last column value.
false
. Do not add a column separator after the last column value.
Fast Clone forces this parameter to false for Oracle targets if the unloaded source tables contain LOB columns and the
export_binary_to_separate_file
parameter is set to true.
Default value: true
If you use DataStreamer to load data to a Greenplum, Netezza, Teradata, or Vertica target, make sure this parameter is set to true.
truncate_numeric_precision
Specifies the number of significant digits to use for rounding down the source numeric values in the output. This parameter truncates only the fractional part of a number.
Valid values: -1 through 40
Default value:
-1
. Fast Clone does not round down the source numeric values.
unload_data_only
Indicates whether to unload source data only and skip the creation of control files and the load script. Valid values are:
true
. Do not create control files and a data load script when Fast Clone unloads source data to .dat files.
false
. Create control files and a data load script when Fast Clone unloads source data to .dat files.
Default value: false
For flat file, Hadoop, and Hive targets, Fast Clone always uses the parameter value of true.
use_asm_global_cache
For Oracle ASM sources, indicates whether Fast Clone caches ASM AUNs in memory. Valid values are true and false.
Default value: true
use_dbms_diskgroup_instead_of_direct
Indicates whether Fast Clone uses the DBMS_DISKGROUP package to read data from ASM sources. Typically, use of the DBMS_DISKGROUP package is significantly slower than reading data directly from ASM sources because the package has a PL/SQL limit of 32,600 bytes per read.
However, if you use the conventional path method and set this parameter to true, Fast Clone unloads data from ASM by using multiple threads. Fast Clone can use multiple threads from a remote computer, with an even data distribution across the threads.
Valid values are true and false.
Default value: false
use_ip_instead_of_file
Indicates whether Fast Clone sends the source data to the Fast Clone Server that is defined by the
ip_instead_of_file
parameter. Valid values are true and false.
Default value: false
use_sid_instead_of_service
Indicates whether to use the Oracle SID instead of the service name when you cannot connect to the source instance by using the instance name. Valid values are true and false.
Default value: false
use_ssl_connection
For Amazon Redshift and Greenplum targets, the protocol that Fast Clone uses to connect to the target database. Valid values are:
true
. Use the TCP/IP protocol.
false
. Use the TCP/IP protocol with the Secure Sockets Layer (SSL).
Default value: false
use_teradata_parallel_transporter
For Teradata targets, indicates whether Fast Clone uses a Teradata Parallel Transporter (TPT) operator to load the source data to the target database. Valid values are true and false.
Default value: false
validate_block_scn
Determines whether to write a warning message to a log file when the SCN value of an unloaded data block is greater than the Start SCN value. The Start SCN value corresponds to point immediately after the checkpoint when Fast Clone started unloading data. Fast Clone compares these values to detect possible data inconsistencies in the unloaded data. Valid values are:
true
. Write a warning message to a log file when a block SCN value is greater than the Start SCN value.
false
. Do not write the warning message.
Default value: false
To use the parameter, you must manually enter it in the cloning configuration file. You cannot enter it at the command line or in the Fast Clone Console.
In the [INDIRECT] section of the configuration file, you can enter the following runtime parameters for the conventional path method:
blob_fetch_chunk_size_for_indirect_kb
Specifies the amount of data that Fast Clone can unload from LOB columns at one time.
Valid values: 1 through 4096
Default value: 128
enforce_oci9_limitations
Indicates whether Fast Clone unloads a single row at a time when a source table contains RAW columns. Valid values are:
true
. Force the
fetch_array_size_for_indirect
parameter to 1 if a source table contains RAW columns.
false
. Always use the
fetch_array_size_for_indirect
parameter.
Default value: true
fetch_array_size_for_indirect
Specifies the number of rows that Fast Clone can unload from the Oracle source database at one time.
Valid values: 1 through 50000
Default value: 500
fetch_blob_as_single_chunk_for_indirect
Indicates whether to unload a single chunk of LOB data that has the size specified by the
fetch_blob_as_single_chunk_for_indirect_kb
parameter. Valid values are:
true
. Unload only a single chunk of LOB data.
false
. Unload all LOB data in multiple chunks.
Default value: false
fetch_blob_as_single_chunk_for_indirect_kb
Specifies the maximum amount of data that Fast Clone unloads from a LOB column if the
fetch_blob_as_single_chunk_for_indirect
parameter is set to true.
Valid values: 64 through 2097151
Default value: 128
oracle_use_direct_file_access_to_fetch_extent_map
Indicates whether to read extent information for parallel unload processing directly from the data file. Specify true to read extent information from the data file.
Default value: false
In the Fast Clone Console, the corresponding
Use direct file access to fetch extent map
option is selected (true) by default.
statement_unload_threads_num
Specifies the maximum number of tables or table partitions that Fast Clone can unload in parallel with the conventional path unload method.
Valid values: 1 through 64
Default value: 1
statement_unload_threads_per_segment_num
Specifies the maximum number of threads that Fast Clone can use to unload data from each table or partition with the conventional path method.
If you use multiple threads for a single table, CPU usage might increase. Usually, multiple threads are used to unload data from large tables. Fast Clone might use fewer threads than this parameter defines because there no reason to create a thread to export a chunk of less than 100 data blocks.