Communities
A collaborative platform to connect and grow with like-minded Informaticans across the globe
Product Communities
Connect and collaborate with Informatica experts and champions
Discussions
Have a question? Start a Discussion and get immediate answers you are looking for
User Groups
Customer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
Get Started
Community Guidelines
Knowledge Center
Troubleshooting documents, product guides, how to videos, best practices, and more
Knowledge Base
One-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and more
Support TV
Video channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much more
Documentation
Information library of the latest product documents
Velocity (Best Practices)
Best practices and use cases from the Implementation team
Learn
Rich resources to help you leverage full capabilities of our products
Trainings
Role-based training programs for the best ROI
Certifications
Get certified on Informatica products. Free, Foundation, or Professional
Product Learning Paths
Free and unlimited modules based on your expertise level and journey
Resources
Library of content to help you leverage the best of Informatica products
Tech Tuesdays Webinars
Most popular webinars on product architecture, best practices, and more
Product Availability Matrix
Product Availability Matrix statements of Informatica products
SupportFlash
Monthly support newsletter
Support Documents
Informatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description Schedule
Product Lifecycle
End of Life statements of Informatica products
Ideas
Events
Change Request Tracking
Marketplace
日本語
English
英語
Español
スペイン語
Deutsch
ドイツ語
Français
フランス語
日本語
日本語
한국어
韓国語
Português
ポルトガル語
中文
中国語
ログイン
サインアップ
Data Engineering Integration
10.4.0
10.5.8
10.5.7
10.5.6
10.5.3
10.5.2
10.5.1
10.5
10.4.1
10.4.0
10.2.2 HotFix 1
10.2.2 Service Pack 1
10.2.2
10.2.1
ユーザーガイド
更新済み : February 2020
Data Engineering Integration
Data Engineering Integration 10.4.0
所有产品
Rename Saved Search
Name
* This field is required
Overwrite saved search
Confirm Deletion
Are you sure you want to delete the saved search?
目次
Search
No Results
はじめに
Informatica Data Engineering Integrationについて
Informatica Data Engineering Integrationの概要
例
Data Engineering Integrationのコンポーネントアーキテクチャ
クライアントおよびツール
アプリケーションサービス
リポジトリ
Hadoopの統合
Hadoopのユーティリティ
Databricksの統合
Data Engineering Integrationのエンジン
Blazeエンジン上のランタイム処理
Blazeエンジン高可用性
アプリケーションタイムラインサーバー
Sparkエンジン上のランタイム処理
Databricks Sparkエンジン上のランタイム処理
Data Engineeringプロセス
手順1。データの収集
手順2。データのクレンジング
手順3。データの変換
手順4。データの処理
手順5。ジョブの監視
データウェアハウス最適化のマッピングの例
マッピング
マッピングの概要
マッピングランタイムプロパティ
検証環境
実行環境
SparkエンジンのJSONレコードの解析
拒否ファイルディレクトリ
マッピング実行のための計算クラスタの変更
複数のマッピングのランタイムプロパティの更新
Hadoop環境でのSqoopマッピング
Sqoopマッピングレベル引数
mまたはnum-mappers
split-by
batch
infaoptimize
infaownername
スキーマ
verbose
Sqoopマッピングの差分データ抽出
マッピングのSqoopプロパティの設定
マッピングでのSqoop引数のパラメータの設定
マッピング出力のバインディング
非ネイティブ環境のマッピングのルールとガイドライン
Blazeエンジンでのマッピングのルールとガイドライン
Sparkエンジンでのマッピングのルールとガイドライン
関数とデータ型の処理(Sparkエンジン)
Databricks Sparkエンジンでのマッピングのルールとガイドライン
非ネイティブ環境でマッピングを実行するワークフロー
非ネイティブ環境で実行するマッピングの設定
マッピング実行プラン
Blazeエンジンの実行プランの詳細
Sparkエンジンの実行プランの詳細
Databricks Sparkエンジンの実行の詳細
実行プランの表示
非ネイティブ環境でのマッピングのトラブルシューティング
ネイティブ環境でのマッピング
データプロセッサのマッピング
HDFSマッピング
HDFSデータ抽出マッピングの例
Hiveマッピング
Hiveマッピングの例
ソーシャルメディアマッピング
Twitterマッピングの例
ネイティブ環境の最適化
グリッドでのデータ処理
パーティションでのデータ処理
パーティションの最適化
高可用性
マッピングの最適化
マッピングの最適化
マッピングの推奨事項と分析
推奨事項
推奨事項の実装
推奨事項のアーカイブ
推奨事項カテゴリの無効化
推奨事項の有効化と無効化
インサイト
分析スプレッドシート
例
一時ステージングテーブルでのデータ圧縮の有効化
手順1.Hadoop接続でのデータ圧縮の有効化
手順2.Hadoop環境でのデータ圧縮の有効化
Hiveターゲットでのパーティションの切り詰め
スケジュール、キュー、およびノードのラベル適用
スケジュール設定とノードラベルの有効化
YARNキューの定義
ノードラベルを使用するためのBlazeエンジンの設定
Data Engineering Recovery
Sqoopパススルーマッピング向けのSparkエンジン最適化
ソース
ソースの概要
PowerExchangeアダプタソース
Databricksのソース
Amazon S3の複合ファイルソース
ADLSの複合ファイルソース
Azure Data Lake Storage Gen2の複合ファイルソース
Azure Blobの複合ファイルソース
Databricks Delta Lake
Databricksソースのルールとガイドライン
ファイルソースHadoop上
Amazon S3の複合ファイルソース
ADLSの複合ファイルソース
Azure Data Lake Storage Gen2の複合ファイルソース
Azure Blobの複合ファイルソース
MapR-FSの複合ファイルソース
HDFSの複合ファイルソース
フラットファイルソースHadoop上
ソースファイル名の生成
Hadoopのリレーショナルソース
HiveソースHadoop上
PreSQLコマンドおよびPostSQLコマンド
Blazeエンジン上のHiveソースのルールとガイドライン
HadoopのSqoopソース
Sqoopを使用したVerticaソースからのデータ読み取り
Sqoopソースのルールとガイドライン
Sqoopクエリのルールとガイドライン
ターゲット
ターゲットの概要
PowerExchangeアダプタターゲット
Databricksのターゲット
Amazon S3の複合ファイルターゲット
ADLSの複合ファイルターゲット
Azure Data Lake Storage Gen2の複合ファイルソース
Azure Blobの複合ファイルターゲット
Databricks Delta Lake
Databricksターゲットのルールとガイドライン
Hadoopでのファイルターゲット
Amazon S3の複合ファイルターゲット
ADLSの複合ファイルターゲット
Azure Blobの複合ファイルターゲット
MapR-FSの複合ファイルターゲット
HDFSの複合ファイルターゲット
フラットファイルターゲットHadoop上
Hadoopでのメッセージターゲット
Hadoopのリレーショナルターゲット
HadoopのHiveターゲット
PreSQLコマンドおよびPostSQLコマンド
Hiveターゲットの切り詰め
アップデートストラテジトランスフォーメーションを使用したHiveターゲットの更新
Blazeエンジン上のHiveターゲットのルールとガイドライン
Hive Warehouse Connector
HadoopのSqoopターゲット
Sqoopターゲットのルールとガイドライン
トランスフォーメーション
トランスフォーメーションの概要
非ネイティブ環境でのアドレスバリデータトランスフォーメーション
Blazeエンジンでのアドレスバリデータトランスフォーメーション
Sparkエンジンでのアドレスバリデータトランスフォーメーション
アドレスバリデータトランスフォーメーションストリーミングマッピングでの
非ネイティブ環境でのアグリゲータトランスフォーメーション
Blazeエンジンでのアグリゲータトランスフォーメーション
Sparkエンジンでのアグリゲータトランスフォーメーション
ストリーミングマッピングでのアグリゲータトランスフォーメーション
Databricks Sparkエンジンでのアグリゲータトランスフォーメーション
非ネイティブ環境での大文字小文字変換トランスフォーメーション
非ネイティブ環境での分類子トランスフォーメーション
非ネイティブ環境での比較トランスフォーメーション
非ネイティブ環境での統合トランスフォーメーション
Blazeエンジンでの統合トランスフォーメーション
Sparkエンジンでの統合トランスフォーメーション
非ネイティブ環境でのデータマスキングトランスフォーメーション
Blazeエンジンでのデータマスキングトランスフォーメーション
Sparkエンジンでのデータマスキングトランスフォーメーション
データマスキングトランスフォーメーションストリーミングマッピングでの
非ネイティブ環境でのデータプロセッサトランスフォーメーション
非ネイティブ環境でのディシジョントランスフォーメーション
Sparkエンジンでのディシジョントランスフォーメーション
非ネイティブ環境での式トランスフォーメーション
Blazeエンジンでの式トランスフォーメーション
Sparkエンジンでの式トランスフォーメーション
ストリーミングマッピングでの式トランスフォーメーション
Databricks Sparkエンジンでの式トランスフォーメーション
非ネイティブ環境でのフィルタトランスフォーメーション
Blazeエンジンでのフィルタトランスフォーメーション
階層型からリレーショナルへのトランスフォーメーション(非ネイティブ環境)
非ネイティブ環境でのJavaトランスフォーメーション
BlazeエンジンでのJavaトランスフォーメーション
SparkエンジンでのJavaトランスフォーメーション
ストリーミングマッピングでのJavaトランスフォーメーション
非ネイティブ環境でのジョイナトランスフォーメーション
Blazeエンジンでのジョイナトランスフォーメーション
Sparkエンジンでのジョイナトランスフォーメーション
ストリーミングマッピングでのジョイナトランスフォーメーション
Databricks Sparkエンジンでのジョイナトランスフォーメーション
非ネイティブ環境でのキージェネレータトランスフォーメーション
非ネイティブ環境でのラベラトランスフォーメーション
非ネイティブ環境でのルックアップトランスフォーメーション
Blazeエンジンでのルックアップトランスフォーメーション
Sparkエンジンでのルックアップトランスフォーメーション
ストリーミングマッピングでのルックアップトランスフォーメーション
Databricks Sparkエンジンでのルックアップトランスフォーメーション
非ネイティブ環境での一致トランスフォーメーション
Blazeエンジンでの一致トランスフォーメーション
Sparkエンジンでの一致トランスフォーメーション
非ネイティブ環境でのマージトランスフォーメーション
非ネイティブ環境でのノーマライザトランスフォーメーション
非ネイティブ環境でのパーサートランスフォーメーション
非ネイティブ環境でのランクトランスフォーメーション
Blazeエンジンでのランクトランスフォーメーション
Sparkエンジンでのランクトランスフォーメーション
ストリーミングマッピングでのランクトランスフォーメーション
Databricks Sparkエンジンでのランクトランスフォーメーション
リレーショナルから階層型へのトランスフォーメーション(非ネイティブ環境)
非ネイティブ環境でのルータートランスフォーメーション
シーケンスジェネレータトランスフォーメーション非ネイティブ環境で
Blazeエンジンでのシーケンスジェネレータトランスフォーメーション
Sparkエンジンでのシーケンスジェネレータトランスフォーメーション
非ネイティブ環境でのソータートランスフォーメーション
Blazeエンジンでのソータートランスフォーメーション
Sparkエンジンでのソータートランスフォーメーション
ストリーミングマッピングでのソータトランスフォーメーション
Databricks Sparkエンジンでのソータートランスフォーメーション
非ネイティブ環境での標準化トランスフォーメーション
非ネイティブ環境での共有体トランスフォーメーション
ストリーミングマッピングでの共有体トランスフォーメーション
非ネイティブ環境でのアップデートストラテジトランスフォーメーション
Blazeエンジンでのアップデートストラテジトランスフォーメーション
Sparkエンジンでのアップデートストラテジトランスフォーメーション
非ネイティブ環境での加重平均トランスフォーメーション
Pythonトランスフォーメーション
Pythonトランスフォーメーションの概要
アクティブPythonトランスフォーメーションとパッシブPythonトランスフォーメーション
データ型の変換
入出力ポートのデータ型
Pythonトランスフォーメーションのポート
Pythonトランスフォーメーションの詳細プロパティ
Pythonトランスフォーメーションのコンポーネント
リソースファイル
Pythonコード
Pythonトランスフォーメーションのルールおよびガイドライン
ストリーミングマッピングでのPythonトランスフォーメーション
Pythonトランスフォーメーションの作成
再利用可能なPythonトランスフォーメーションの作成
再利用不可能なPythonトランスフォーメーションの作成
例: IDカラムの非パーティション化データへの追加
例: 最も高い給与を検索するパーティションの使用
ユースケース: トレーニング済みモデルを操作可能にする
クラスタワークフロー
クラスタワークフローの概要
クラスタワークフローのコンポーネント
クラスタワークフロープロセス
クラスタの作成タスクのプロパティ
Amazon EMRの詳細プロパティ
全般オプション
マスタインスタンスグループのオプション
コアインスタンスグループのオプション
タスクインスタンスグループのオプション
追加オプション
Azure HDInsightの詳細プロパティ
Azure Databricksの詳細プロパティ
全般オプション
詳細オプション
AWS Databricksの詳細プロパティ
全般オプション
詳細オプション
Blazeエンジンの詳細プロパティ
Hiveメタストアデータベースの詳細プロパティ
マッピングタスクのプロパティ
クラスタの削除タスクの追加
ワークフローのデプロイと実行
Azure HDInsightクラスタワークフロージョブの監視
プロファイル
プロファイルの概要
ネイティブ環境
Hadoop環境
Sqoopデータソースのカラムプロファイル
サンプリングオプション
Informatica Developerでの単一のデータオブジェクトプロファイルの作成
Informatica Developerでのエンタープライズ検出プロファイルの作成
Informatica Analystでのカラムプロファイルの作成
Informatica Analystでのエンタープライズ検出プロファイルの作成
Informatica Analystでのスコアカードの作成
プロファイルの監視
プロファイリング機能のサポート
トラブルシューティング
監視
監視の概要
Hadoop環境のログ
YARN Webユーザーインタフェース
監視URLへのアクセス
AdministratorツールでのHadoop環境ログの表示
マッピングの監視
Blazeエンジンの監視
Blazeジョブ監視アプリケーション
Blazeサマリレポート
個々のセグメントで費やされる時間
マッピングプロパティ
タスクレットの実行時間
選択したタスクレットの情報
Blazeエンジンのログ
Blazeログの表示
オーケストレータのサンセット時間
Blaze監視のトラブルシューティング
Sparkエンジン監視
Hiveタスクの表示
Sparkエンジンのログ
Sparkログの表示
Sparkエンジン監視のトラブルシューティング
階層データ処理
階層データ処理の概要
マッピングの開発方法階層データの処理
復号データ型
arrayデータ型
Mapデータ型
Structデータ型
複合データ型のルールとガイドライン
複合ポート
トランスフォーメーション内の複合ポート
複合ポートのルールとガイドライン
複合ポートの作成
複合データ型定義
ネストされたデータ型定義
複合データ型定義のルールとガイドライン
複合データ型定義の作成
複合データ型定義のインポート
型設定
配列ポートのタイプ設定の変更
マップポートのタイプ設定の変更
構造ポートの型設定の指定
複合演算子
添字演算子を使用した配列要素の抽出
ドット演算子を使用した構造要素の抽出
複合関数
階層データのプレビュー
階層データプレビュープロセス
データプレビューインタフェーステーブル
データビューア
データのエクスポート
階層タイプパネル
階層データのプレビュー
トランスフォーメーションでの階層データのプレビュー
階層データプレビューのルールおよびガイドライン
階層データ処理設定
階層データの変換
リレーショナルデータまたは階層データの構造データへの変換
構造ポートの作成
リレーショナルデータまたは階層データのネストされた構造データへの変換
ネストされた複合ポートの作成
階層データからの要素の抽出
複合ポートからの要素の抽出
階層データのフラット化
複合ポートのフラット化
スキーマが変更された階層データの処理
スキーマが変更された階層データの処理の概要
階層データのスキーマの変更を処理する動的マッピングの開発方法
動的複合ポート
動的ポートと動的複合ポート
トランスフォーメーション内の動的複合ポート
動的複合ポートの入力ルール
動的配列の入力ルール
動的マップの入力ルール
動的構造の入力ルール
動的複合ポートのポートセレクタ
動的式
例 - 動的構造を構築する動的式
複合演算子
複合関数
動的複合ポートのルールおよびガイドライン
最適化されたマッピング
ブロックチェーン
ブロックチェーンの概要
ブロックチェーンデータオブジェクト
レスポンスポート
ブロックチェーンデータオブジェクトの概要プロパティ
ブロックチェーンデータオブジェクトの作成
ブロックチェーンデータオブジェクト操作
ブロックチェーンデータオブジェクトの読み取り操作プロパティ
ブロックチェーンデータオブジェクトの書き込み操作プロパティ
ブロックチェーンデータオブジェクト操作の作成
ユースケース: ブロックチェーンソースを使用した車両ライフサイクルのサービス向上
マッピングの概要
インテリジェント構造モデル
インテリジェント構造モデルの概要
インテリジェント構造検出プロセス
ユースケース
マッピングでのインテリジェント構造モデルの使用
インテリジェント構造モデルのルールとガイドライン
インテリジェント構造モデルを使用してデータを処理するためのマッピングの開発および実行方法
マッピングの例
Cloud Data Integrationでのインテリジェント構造モデルの作成
作業を開始する前に
Informatica Intelligent Cloud Servicesアカウントの作成
インテリジェント構造モデルの作成
インテリジェント構造モデルのエクスポート
ステートフルコンピューティング
ステートフルコンピューティングの概要
ウィンドウ化構成
フレーム
パーティションキーおよびオーダーキー
ウィンドウ化構成のルールとガイドライン
ウィンドウ関数
LEAD
LAG
ウィンドウ関数としての集計関数
集計オフセット
ネストされた集計関数
ウィンドウ関数のルールとガイドライン
ウィンドウ化例
財務プランの例
GPS pingの例
ウィンドウ関数としての集計関数例
接続
接続
クラウドプロビジョニング設定
AWSクラウドプロビジョニング設定のプロパティ
全般プロパティ
権限
EC2設定
Azureクラウドプロビジョニング設定のプロパティ
認証の詳細
ストレージアカウントの詳細
クラスタデプロイメントの詳細
外部Hiveメタストアの詳細
Databricksクラウドプロビジョニング設定のプロパティ
Amazon Redshift接続のプロパティ
Amazon S3接続のプロパティ
ブロックチェーン接続プロパティ
Cassandra接続のプロパティ
Databricks接続プロパティ
Google Analytics接続のプロパティ
Google BigQuery接続のプロパティ
Google Cloud Spanner接続のプロパティ
Google Cloud Storage接続のプロパティ
Hadoop接続プロパティ
Hadoopクラスタプロパティ
共通プロパティ
拒否ディレクトリのプロパティ
Blaze設定
Spark設定
HDFS接続プロパティ
HBase接続プロパティ
MapR-DBのHBase接続のプロパティ
Hive接続のプロパティ
JDBC接続のプロパティ
JDBC接続文字列
Sqoopの接続レベルの引数
JDBC V2接続のプロパティ
Kafka接続のプロパティ
Microsoft Azure Blobストレージ接続のプロパティ
Microsoft Azure Cosmos DB SQL API接続のプロパティ
Microsoft Azure Data Lake Storage Gen1接続のプロパティ
Microsoft Azure Data Lake Storage Gen2接続プロパティ
Microsoft Azure SQL Data Warehouse接続プロパティ
Snowflake接続プロパティ
ソースまたはターゲットにアクセスするための接続の作成
Hadoop接続の作成
Hadoop接続プロパティの設定
クラスタ環境変数
クラスタのライブラリパス
共通する詳細プロパティ
Blazeエンジン詳細プロパティ
Sparkの詳細プロパティ
データ型リファレンス
データ型リファレンスの概要
非ネイティブ環境でのトランスフォーメーションデータ型のサポート
複合ファイルデータ型とトランスフォーメーションデータ型
Avroのデータ型とトランスフォーメーションデータ型
JSONのデータ型とトランスフォーメーションデータ型
ORCのデータ型とトランスフォーメーションデータ型
Parquetのデータ型とトランスフォーメーションデータ型
データ型のルールとガイドライン
Hiveのデータ型とトランスフォーメーションデータ型
Hiveの複合データ型
Sqoopのデータ型
Auroraのデータ型
IBM DB2およびDB2 for z/OSのデータ型
Greenplumのデータ型
Microsoft SQL Serverデータ型
Netezzaのデータ型
Oracleのデータ型
Teradataのデータ型
Sqoop用のTDCH専用コネクタを備えたTeradataのデータ型
Verticaのデータ型
関数リファレンス
非ネイティブ環境での関数サポート
関数とデータ型の処理
Data Engineering Integration 10.4.0
Help for Users
ユーザーガイド
マッピング
マッピング実行プラン
Databricks Sparkエンジンの実行の詳細
ユーザーガイド
ユーザーガイド
10.4.0
10.5.7
10.5.1
10.2.2 HotFix 1
10.2.2 Service Pack 1
10.2.2
前へ
次へ
Databricks Sparkエンジンの実行の詳細
Databricks Sparkエンジンの実行の詳細
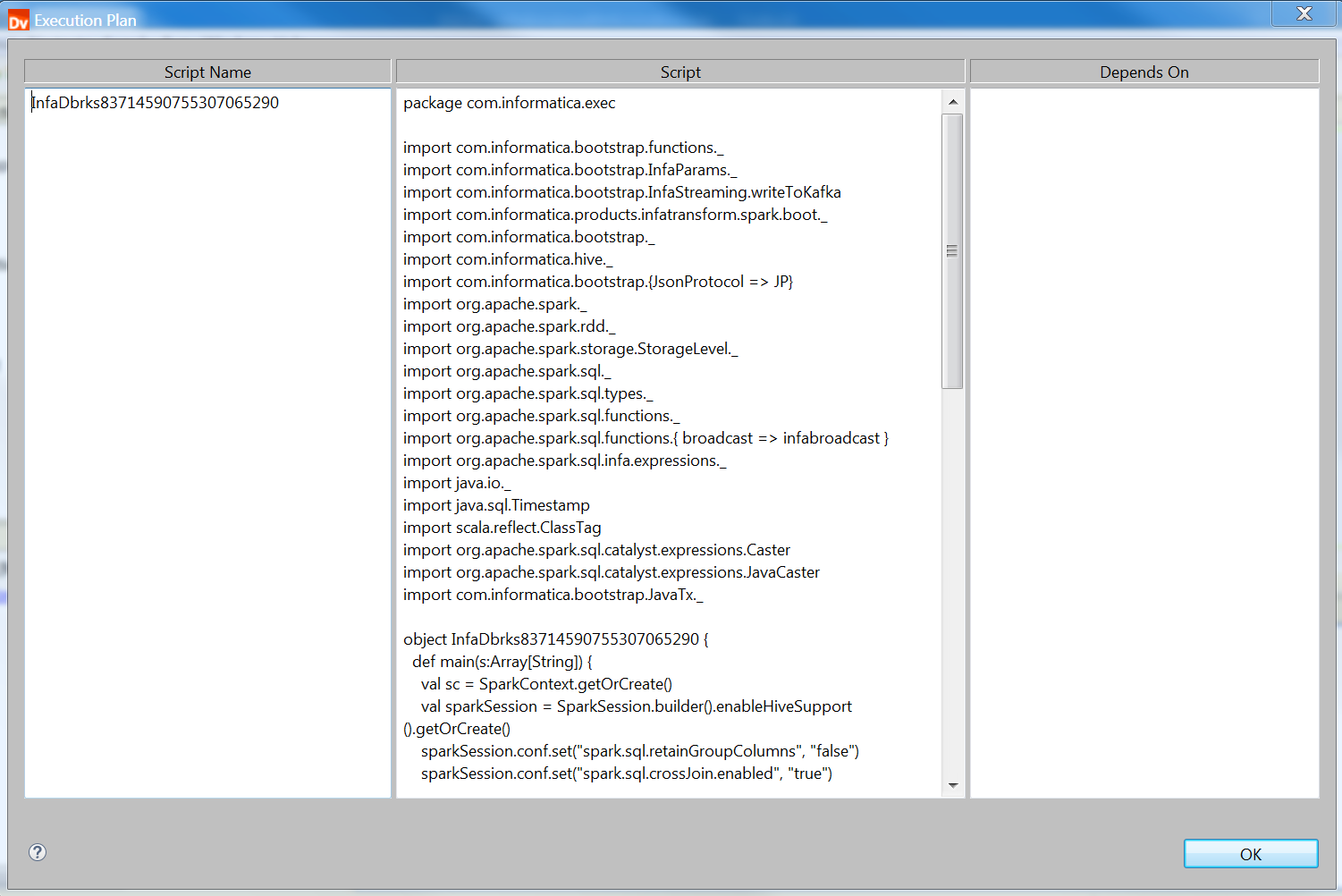
Databricks Sparkエンジンの実行プランの詳細を、AdministratorツールまたはDeveloper toolから表示できます。
Databricks Sparkエンジンの実行プランには、Databricks Sparkエンジンで実行されるScaleコードが表示されます。
次の図は、Databricks Sparkエンジンで実行されるマッピングの実行プランを示します。
Databricks Sparkエンジンの実行プランの詳細は次のとおりです。
スクリプトID。Databricks Sparkエンジンスクリプトの一意の識別子。
スクリプト。データ統合サービスがマッピングロジックに基づいて生成したスカラコード。
依存対象。このスクリプトが依存するタスクです。タスクには、他のスクリプトやデータ統合サービスタスクが含まれます。
マッピング実行プラン
行動
ガイドをダウンロード
ページをウォッチ
フィードバックを送信
リソース
コミュニティ
Knowledge Base
Success Portal
トップに戻る
前へ
次へ